Pengenalan
 Kecerdasan buatan adalah tentang menggunakan mesin untuk meningkatkan kehidupan dan gaya hidup orang ramai dengan menjadikan kehidupan duniawi mereka menarik dan tugas berlebihan mudah. AI tidak sepatutnya menjadi kuasa yang mendominasi tetapi pelengkap yang berfungsi seiring dengan manusia untuk menyelesaikan perkara yang tidak munasabah dan membuka jalan kepada evolusi kolektif.
Kecerdasan buatan adalah tentang menggunakan mesin untuk meningkatkan kehidupan dan gaya hidup orang ramai dengan menjadikan kehidupan duniawi mereka menarik dan tugas berlebihan mudah. AI tidak sepatutnya menjadi kuasa yang mendominasi tetapi pelengkap yang berfungsi seiring dengan manusia untuk menyelesaikan perkara yang tidak munasabah dan membuka jalan kepada evolusi kolektif.
Buat masa ini, kami sedang berjalan di jalan yang betul dengan penemuan penting yang berlaku di seluruh industri dengan bantuan AI. Jika anda mengambil penjagaan kesihatan sebagai contoh, sistem AI yang disertakan dengan model pembelajaran mesin membantu pakar memahami kanser dengan lebih baik dan menghasilkan rawatan untuknya. Gangguan dan kebimbangan neurologi seperti PTSD sedang dirawat dengan bantuan AI. Vaksin sedang dibangunkan pada kadar yang pantas terima kasih kepada ujian klinikal dan simulasi yang dikuasakan AI.
Bukan sahaja penjagaan kesihatan, setiap industri atau segmen yang disentuh AI sedang direvolusikan. Kenderaan autonomi, kedai serbaneka pintar, barang boleh pakai seperti FitBit dan juga kamera telefon pintar kami mampu menangkap imej wajah kami yang lebih baik dengan AI.
Terima kasih kepada inovasi yang berlaku dalam ruang AI, syarikat memasuki spektrum dengan pelbagai kes penggunaan dan penyelesaian. Disebabkan ini, pasaran AI global dijangka mencapai nilai pasaran sekitar $267bn menjelang akhir tahun 2027. Selain itu, kira-kira 37% daripada perniagaan di luar sana sudah pun melaksanakan penyelesaian AI ke dalam proses dan produk mereka.
Lebih menarik, hampir 77% daripada produk dan perkhidmatan yang kami gunakan hari ini dikuasakan oleh AI. Dengan konsep teknologi meningkat dengan ketara merentas menegak, bagaimanakah perniagaan berjaya melakukan sesuatu yang mustahil dengan AI?

 Bagaimanakah peranti semudah jam tangan meramalkan serangan jantung pada manusia dengan tepat? Bagaimanakah mungkin kereta dan kereta yang selalu memerlukan pemandu tiba-tiba kurang memandu di jalan raya?
Bagaimanakah peranti semudah jam tangan meramalkan serangan jantung pada manusia dengan tepat? Bagaimanakah mungkin kereta dan kereta yang selalu memerlukan pemandu tiba-tiba kurang memandu di jalan raya?
Bagaimanakah chatbots membuatkan kita percaya bahawa kita sedang bercakap dengan manusia lain di seberang?
Jika anda memerhatikan jawapan kepada setiap soalan, ia bermuara kepada satu elemen sahaja – DATA. Data terletak di tengah-tengah semua operasi dan proses khusus AI. Ia adalah data yang membantu mesin memahami konsep, memproses input dan memberikan hasil yang tepat.
Semua penyelesaian AI utama yang ada di luar sana adalah semua produk daripada proses penting yang kami panggil pengumpulan data atau pemerolehan data atau data latihan AI.
Panduan yang luas ini adalah tentang membantu anda memahami apa itu dan mengapa ia penting.
Apakah Pengumpulan Data AI?
Mesin tidak mempunyai fikiran mereka sendiri. Ketiadaan konsep abstrak ini menjadikan mereka tidak mempunyai pendapat, fakta dan keupayaan seperti penaakulan, kognisi dan banyak lagi. Ia hanyalah kotak tidak alih atau peranti yang menduduki ruang. Untuk mengubahnya menjadi medium yang berkuasa, anda memerlukan algoritma dan lebih penting lagi data.
 Algoritma yang dibangunkan memerlukan sesuatu untuk diusahakan dan diproses dan sesuatu itu adalah data yang relevan, kontekstual dan terkini. Proses mengumpul data sedemikian untuk mesin untuk memenuhi tujuan yang dimaksudkan dipanggil pengumpulan data AI.
Algoritma yang dibangunkan memerlukan sesuatu untuk diusahakan dan diproses dan sesuatu itu adalah data yang relevan, kontekstual dan terkini. Proses mengumpul data sedemikian untuk mesin untuk memenuhi tujuan yang dimaksudkan dipanggil pengumpulan data AI.
Setiap produk atau penyelesaian yang didayakan AI yang kami gunakan hari ini dan hasil yang mereka tawarkan berpunca daripada latihan, pembangunan dan pengoptimuman selama bertahun-tahun. Daripada peranti yang menawarkan laluan navigasi kepada sistem kompleks yang meramalkan kegagalan peralatan lebih awal, setiap entiti telah melalui latihan AI selama bertahun-tahun untuk dapat menyampaikan hasil dengan tepat.
Pengumpulan data AI ialah langkah awal dalam proses pembangunan AI yang sejak awal lagi menentukan keberkesanan dan kecekapan sistem AI. Ini ialah proses mendapatkan set data yang berkaitan daripada pelbagai sumber yang akan membantu model AI memproses butiran dengan lebih baik dan menghasilkan hasil yang bermakna.




Bagaimana untuk Mengumpul data untuk Pembelajaran Mesin?
 Di sinilah keadaan mula menjadi sedikit rumit. Dari awal, nampaknya anda mempunyai penyelesaian kepada masalah dunia sebenar dalam fikiran, anda tahu AI akan menjadi cara yang ideal untuk mengatasinya dan anda telah membangunkan model anda. Tetapi sekarang, anda berada dalam fasa penting di mana anda perlu memulakan proses latihan AI anda. Anda memerlukan data latihan AI yang banyak dengan anda untuk menjadikan model anda mempelajari konsep dan menyampaikan hasil. Anda juga memerlukan data pengesahan untuk menguji keputusan anda dan mengoptimumkan algoritma anda.
Di sinilah keadaan mula menjadi sedikit rumit. Dari awal, nampaknya anda mempunyai penyelesaian kepada masalah dunia sebenar dalam fikiran, anda tahu AI akan menjadi cara yang ideal untuk mengatasinya dan anda telah membangunkan model anda. Tetapi sekarang, anda berada dalam fasa penting di mana anda perlu memulakan proses latihan AI anda. Anda memerlukan data latihan AI yang banyak dengan anda untuk menjadikan model anda mempelajari konsep dan menyampaikan hasil. Anda juga memerlukan data pengesahan untuk menguji keputusan anda dan mengoptimumkan algoritma anda.
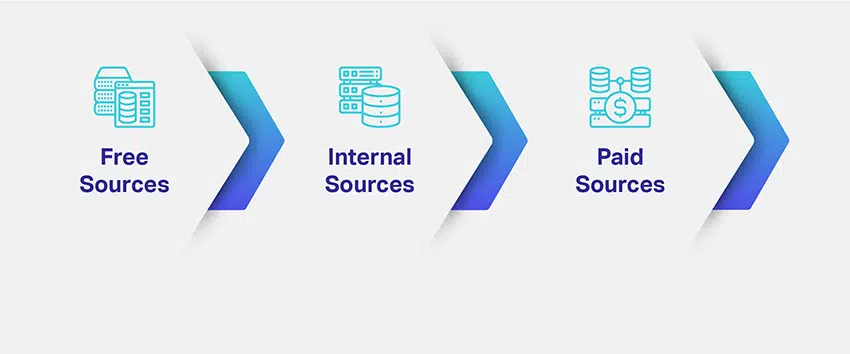
Jadi, bagaimana anda mendapatkan data anda? Apakah data yang anda perlukan dan berapa banyak daripadanya? Apakah pelbagai sumber untuk mengambil data yang berkaitan?
Syarikat menilai niche dan tujuan model ML mereka dan mencatatkan cara yang berpotensi untuk mendapatkan set data yang berkaitan. Menentukan jenis data yang diperlukan menyelesaikan sebahagian besar kebimbangan anda tentang sumber data. Untuk memberi anda idea yang lebih baik, terdapat saluran, jalan, sumber atau medium yang berbeza untuk pengumpulan data:
Bagaimanakah data buruk menjejaskan cita-cita AI anda?
Kami menyenaraikan tiga sumber data yang paling biasa atas sebab anda akan mempunyai idea tentang cara mendekati pengumpulan dan penyumberan data. Walau bagaimanapun, pada ketika ini, menjadi penting untuk memahami bahawa keputusan anda selalu boleh menentukan nasib penyelesaian AI anda.
Sama seperti cara data latihan AI berkualiti tinggi boleh membantu model anda memberikan hasil yang tepat dan tepat pada masanya, data latihan yang buruk juga boleh memecahkan model AI anda, memesongkan hasil, memperkenalkan berat sebelah dan menawarkan akibat lain yang tidak diingini.
Tetapi mengapa ini berlaku? Bukankah sebarang data sepatutnya melatih dan mengoptimumkan model AI anda? Sejujurnya, tidak. Mari kita fahami ini dengan lebih lanjut.
Data Buruk – Apa Itu?
 Data buruk ialah sebarang data yang tidak relevan, tidak betul, tidak lengkap atau berat sebelah. Terima kasih kepada strategi pengumpulan data yang kurang jelas, kebanyakan saintis data dan pakar anotasi terpaksa bekerja pada data yang buruk.
Data buruk ialah sebarang data yang tidak relevan, tidak betul, tidak lengkap atau berat sebelah. Terima kasih kepada strategi pengumpulan data yang kurang jelas, kebanyakan saintis data dan pakar anotasi terpaksa bekerja pada data yang buruk.
Perbezaan antara data tidak berstruktur dan buruk ialah cerapan dalam data tidak berstruktur ada di mana-mana. Tetapi pada dasarnya, mereka boleh berguna tanpa mengira. Dengan meluangkan masa tambahan, saintis data masih boleh mengekstrak maklumat yang berkaitan daripada set data tidak berstruktur. Walau bagaimanapun, itu tidak berlaku dengan data yang buruk. Set data ini tidak mengandungi cerapan/terhad atau maklumat yang berharga atau berkaitan dengan projek AI anda atau tujuan latihannya.
Oleh itu, apabila anda mendapatkan set data anda daripada sumber percuma atau mempunyai titik sentuh data dalaman yang longgar, kemungkinan besar anda akan memuat turun atau menjana data yang tidak baik. Apabila saintis anda mengusahakan data yang tidak baik, anda bukan sahaja membuang masa manusia tetapi mendorong pelancaran produk anda juga.
Jika anda masih tidak jelas tentang perkara yang boleh dilakukan oleh data buruk terhadap cita-cita anda, berikut ialah senarai ringkas:
- Anda menghabiskan berjam-jam untuk mendapatkan data buruk dan membuang masa, usaha dan wang untuk sumber.
- Data buruk boleh mendatangkan masalah undang-undang kepada anda, jika tidak disedari dan boleh menurunkan kecekapan AI anda
. - Apabila anda mengambil produk anda dilatih mengenai data buruk secara langsung, ia menjejaskan pengalaman pengguna
- Data yang tidak baik boleh menjadikan keputusan dan inferens berat sebelah, yang boleh membawa tindak balas seterusnya.
Jadi, jika anda tertanya-tanya jika ada penyelesaian untuk ini, sebenarnya ada.
Pembekal Data Latihan AI untuk menyelamatkan
 Salah satu penyelesaian asas ialah mencari vendor data (sumber berbayar). Pembekal data latihan AI memastikan perkara yang anda terima adalah tepat dan relevan dan anda mempunyai set data dihantar kepada anda dalam bentuk berstruktur. Anda tidak perlu terlibat dalam kerumitan bergerak dari portal ke portal untuk mencari set data.
Salah satu penyelesaian asas ialah mencari vendor data (sumber berbayar). Pembekal data latihan AI memastikan perkara yang anda terima adalah tepat dan relevan dan anda mempunyai set data dihantar kepada anda dalam bentuk berstruktur. Anda tidak perlu terlibat dalam kerumitan bergerak dari portal ke portal untuk mencari set data.
Apa yang anda perlu lakukan ialah mengambil data dan melatih model AI anda untuk kesempurnaan. Dengan itu, kami pasti soalan anda yang seterusnya adalah mengenai perbelanjaan yang terlibat dalam bekerjasama dengan vendor data. Kami faham bahawa sesetengah daripada anda sudah bekerja mengikut bajet mental dan itulah yang kami tuju seterusnya.
Faktor yang perlu dipertimbangkan apabila menghasilkan Belanjawan yang berkesan untuk Projek Pengumpulan Data anda
Latihan AI ialah pendekatan yang sistematik dan itulah sebabnya belanjawan menjadi sebahagian daripadanya. Faktor seperti RoI, ketepatan keputusan, metodologi latihan dan banyak lagi harus dipertimbangkan sebelum melabur sejumlah besar wang ke dalam pembangunan AI. Ramai pengurus projek atau pemilik perniagaan meraba-raba pada peringkat ini. Mereka membuat keputusan tergesa-gesa yang membawa perubahan yang tidak dapat dipulihkan dalam proses pembangunan produk mereka, akhirnya memaksa mereka untuk berbelanja lebih.
Walau bagaimanapun, bahagian ini akan memberi anda cerapan yang betul. Apabila anda sedang bekerja mengikut bajet untuk latihan AI, tiga perkara atau faktor tidak dapat dielakkan.

Mari lihat setiap satu secara terperinci.
Jumlah data yang anda perlukan
Kami telah mengatakan selama ini bahawa kecekapan dan ketepatan model AI anda bergantung pada sejauh mana ia dilatih. Ini bermakna bahawa lebih banyak jumlah set data, lebih banyak pembelajaran. Tetapi ini sangat kabur. Untuk meletakkan nombor pada tanggapan ini, Penyelidikan Dimensi menerbitkan laporan yang mendedahkan bahawa perniagaan memerlukan sekurang-kurangnya 100,000 set data sampel untuk melatih model AI mereka.
Dengan 100,000 set data, kami maksudkan 100,000 set data berkualiti dan berkaitan. Set data ini harus mempunyai semua atribut, anotasi dan cerapan penting yang diperlukan untuk algoritma dan model pembelajaran mesin anda untuk memproses maklumat dan melaksanakan tugas yang dimaksudkan.
Dengan ini ialah peraturan umum, mari kita fahami lebih lanjut bahawa volum data yang anda perlukan juga bergantung pada faktor rumit lain iaitu kes penggunaan perniagaan anda. Perkara yang anda ingin lakukan dengan produk atau penyelesaian anda juga menentukan jumlah data yang anda perlukan. Sebagai contoh, perniagaan yang membina enjin pengesyoran akan mempunyai keperluan volum data yang berbeza daripada syarikat yang membina chatbot.
Strategi Harga Data
Apabila anda selesai memuktamadkan jumlah data yang sebenarnya anda perlukan, anda perlu mengusahakan strategi penetapan harga data seterusnya. Ini, secara ringkas, bermaksud cara anda membayar untuk set data yang anda peroleh atau jana.
Secara umum, ini ialah strategi harga konvensional yang diikuti dalam pasaran:
| Jenis data | Strategi Penentuan harga |
|---|---|
| Harga setiap fail gambar | |
| Harga setiap saat, minit, satu jam, atau bingkai individu | |
| Harga sesaat, satu minit, atau sejam | |
| Harga setiap perkataan atau ayat |
Tapi tunggu. Ini sekali lagi merupakan peraturan biasa. Kos sebenar untuk mendapatkan set data juga bergantung pada faktor seperti:
- Segmen pasaran yang unik, demografi atau geografi dari mana set data perlu diperolehi
- Kerumitan kes penggunaan anda
- Berapa banyak data yang anda perlukan?
- Masa anda untuk memasarkan
- Sebarang keperluan yang disesuaikan dan banyak lagi
Jika anda perhatikan, anda akan tahu bahawa kos untuk memperoleh kuantiti pukal imej untuk projek AI anda mungkin lebih rendah tetapi jika anda mempunyai terlalu banyak spesifikasi, harga boleh meningkat.
Strategi Penyumberan Anda
Ini rumit. Seperti yang anda lihat, terdapat cara yang berbeza untuk menjana atau sumber data untuk model AI anda. Akal sehat akan menentukan bahawa sumber percuma adalah yang terbaik kerana anda boleh memuat turun volum set data yang diperlukan secara percuma tanpa sebarang komplikasi.
Pada masa ini, nampaknya juga sumber berbayar terlalu mahal. Tetapi di sinilah lapisan komplikasi ditambah. Apabila anda mendapatkan set data daripada sumber percuma, anda menghabiskan lebih banyak masa dan usaha untuk membersihkan set data anda, menyusunnya ke dalam format khusus perniagaan anda dan kemudian menganotasinya secara individu. Anda menanggung kos operasi dalam proses itu.
Dengan sumber berbayar, pembayaran adalah sekali sahaja dan anda juga mendapat set data sedia mesin di tangan pada masa yang anda perlukan. Keberkesanan kos adalah sangat subjektif di sini. Jika anda rasa anda mampu meluangkan masa untuk menganotasi set data percuma, anda boleh membuat belanjawan sewajarnya. Dan jika anda percaya persaingan anda sengit dan dengan masa yang terhad untuk memasarkan, anda boleh mencipta kesan riak di pasaran, anda harus memilih sumber berbayar.
Belanjawan adalah tentang memecahkan butiran khusus dan mentakrifkan dengan jelas setiap serpihan. Ketiga-tiga faktor ini harus menjadi panduan kepada anda untuk proses belanjawan latihan AI anda pada masa hadapan.
Adakah anda menjimatkan perbelanjaan dengan Pemerolehan Data dalaman?
 Semasa membuat belanjawan, kami meneroka cara sumber percuma memaksa anda untuk berbelanja lebih dalam jangka panjang. Pada ketika itu, anda secara automatik akan tertanya-tanya tentang keberkesanan kos proses pemerolehan data dalaman.
Semasa membuat belanjawan, kami meneroka cara sumber percuma memaksa anda untuk berbelanja lebih dalam jangka panjang. Pada ketika itu, anda secara automatik akan tertanya-tanya tentang keberkesanan kos proses pemerolehan data dalaman.
Kami tahu bahawa anda masih teragak-agak tentang sumber berbayar dan itulah sebabnya bahagian ini akan menghapuskan keraguan anda tentangnya dan menjelaskan kos tersembunyi yang terlibat dalam penjanaan data dalaman.
Adakah Pemerolehan Data Dalaman Mahal?
Ya betul!
Sekarang, inilah jawapan yang terperinci. Perbelanjaan ialah apa sahaja yang anda belanjakan. Semasa membincangkan sumber percuma, kami mendedahkan anda membelanjakan wang, masa & usaha dalam proses. Ini terpakai kepada pemerolehan data dalaman juga.
 Oleh kerana anda mempunyai titik sentuh atau corong data yang ditentukan tersuai, ini tidak bermakna anda akan mempunyai set data sedia mesin akhirnya. Data yang anda jana masih kebanyakannya mentah dan tidak berstruktur. Anda mungkin mempunyai semua data yang anda perlukan di satu tempat tetapi kandungan data akan berada di mana-mana.
Oleh kerana anda mempunyai titik sentuh atau corong data yang ditentukan tersuai, ini tidak bermakna anda akan mempunyai set data sedia mesin akhirnya. Data yang anda jana masih kebanyakannya mentah dan tidak berstruktur. Anda mungkin mempunyai semua data yang anda perlukan di satu tempat tetapi kandungan data akan berada di mana-mana.
Akhirnya, anda akhirnya akan berbelanja untuk membayar pekerja anda, saintis data, pencatat, profesional jaminan kualiti dan banyak lagi. Anda juga akan membelanjakan langganan untuk alatan anotasi dan
penyelenggaraan CMS, CRM dan perbelanjaan infrastruktur lain.
Selain itu, set data pasti mempunyai kebimbangan berat sebelah dan ketepatan, yang anda perlukan untuk menyusunnya secara manual. Dan jika anda mempunyai isu pergeseran dalam pasukan data latihan AI anda, anda perlu berbelanja untuk merekrut ahli baharu, mengarahkan mereka kepada proses anda, melatih mereka menggunakan alatan anda dan banyak lagi.
Anda akhirnya akan berbelanja lebih daripada apa yang akhirnya anda akan buat dalam jangka masa yang lebih lama. Terdapat juga perbelanjaan anotasi. Pada bila-bila masa tertentu, jumlah kos yang ditanggung untuk bekerja dengan data dalaman ialah:
Kos Ditanggung = Bilangan Anotator * Kos setiap annotator + Kos platform
Jika kalendar latihan AI anda dijadualkan selama berbulan-bulan, bayangkan perbelanjaan yang anda akan tanggung secara konsisten. Jadi, adakah ini penyelesaian yang ideal untuk kebimbangan pemerolehan data atau adakah terdapat sebarang alternatif?
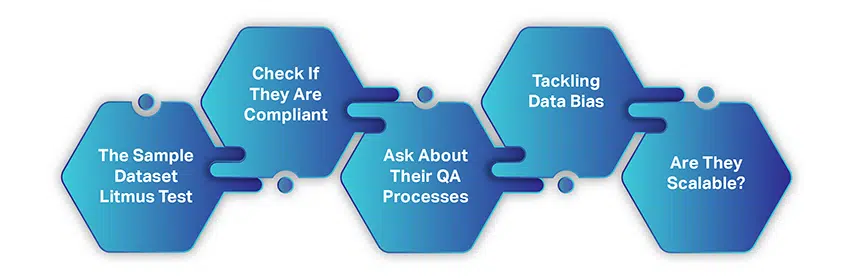
Bagaimana untuk memilih Syarikat Pengumpulan Data AI yang betul
Memilih syarikat pengumpulan data AI tidaklah rumit atau memakan masa seperti mengumpul data daripada sumber percuma. Hanya terdapat beberapa faktor mudah yang perlu anda pertimbangkan dan kemudian berjabat tangan untuk kerjasama.
Apabila anda mula mencari vendor data, kami menganggap bahawa anda telah mengikuti dan mempertimbangkan apa sahaja yang telah kami bincangkan setakat ini. Walau bagaimanapun, berikut adalah ringkasan ringkas:
- Anda mempunyai kes penggunaan yang jelas dalam fikiran
- Segmen pasaran dan keperluan data anda telah ditetapkan dengan jelas
- Belanjawan anda adalah tepat
- Dan anda mempunyai idea tentang jumlah data yang anda perlukan
Dengan item ini ditandakan, mari kita fahami bagaimana anda boleh mencari pembekal perkhidmatan data latihan yang ideal.