
Sistem Pengecaman Pertuturan Automatik dan pembantu maya seperti Siri, Alexa dan Cortana telah menjadi bahagian biasa dalam kehidupan kita. Pergantungan kita kepada mereka semakin meningkat dengan ketara apabila mereka semakin bijak. Daripada menghidupkan lampu kepada membuat panggilan kepada menukar saluran TV, kami memanfaatkan teknologi pintar ini untuk menyelesaikan tugas biasa.
Namun, pernahkah anda terfikir bagaimana sistem pengecaman pertuturan ini berfungsi?
Nah, blog ini akan mendidik anda tentang beberapa asas Pengecaman Pertuturan Automatik. Selain itu, kami akan meneroka kerjanya dan cara pembantu maya berfungsi seperti Siri dibina.
Apakah Pengecaman Pertuturan Automatik?
Automatic Speech Recognition (ASR) ialah perisian yang membolehkan sistem komputer menukar pertuturan manusia kepada teks, memanfaatkan pelbagai kecerdasan buatan dan algoritma pembelajaran mesin.
Selepas menukar dan menganalisis arahan yang diberikan, komputer bertindak balas dengan output yang sesuai untuk pengguna. ASR mula diperkenalkan pada tahun 1962, dan sejak itu, ia terus meningkatkan operasinya dan mendapat perhatian besar kerana aplikasi popular seperti Alexa dan Siri.
Apakah Proses Pengumpulan Ucapan untuk Latihan Model ASR?
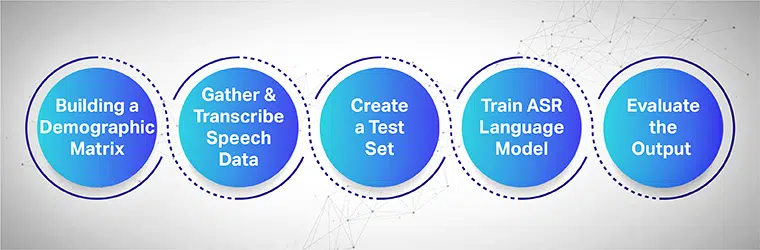
Pengumpulan ucapan bertujuan untuk mengumpulkan beberapa sampel rakaman dari pelbagai kawasan yang digunakan untuk memberi makan dan melatih model ASR. Sistem ASR memberikan kecekapan tertinggi apabila set data pertuturan & audio yang besar dikumpul dan diberikan kepada sistemnya.
Untuk berfungsi dengan lancar, set data pertuturan yang dikumpul mesti mengandungi semua demografi sasaran, bahasa, aksen dan dialek. Proses berikut mempamerkan cara melatih model pembelajaran mesin dalam berbilang langkah:
Mulakan dengan Membina Matriks Demografi
Terutamanya mengumpul data untuk demografi yang berbeza seperti lokasi, jantina, bahasa, umur dan aksen. Juga, pastikan untuk menangkap pelbagai bunyi persekitaran seperti bunyi jalanan, bunyi bilik menunggu, bunyi pejabat awam, dll.
Kumpul dan Transkripsikan Data Ucapan
Langkah seterusnya ialah mengumpul sampel audio dan pertuturan manusia berdasarkan lokasi geografi yang berbeza untuk melatih model ASR anda. Ia merupakan satu langkah yang penting dan memerlukan pakar manusia untuk melakukan pengucapan perkataan yang panjang dan pendek untuk mendapatkan rasa ayat yang tulen dan mengulangi ayat yang sama dalam loghat dan dialek yang berbeza.
Buat Set Ujian Berasingan
Sebaik sahaja anda telah mengumpulkan teks yang ditranskripsi, langkah seterusnya ialah memasangkannya dengan data audio yang sepadan. Kemudian, bahagikan data dengan lebih lanjut dan masukkan satu pernyataan daripadanya. Kini, daripada pasangan data tersegmen, anda boleh menarik data rawak daripada satu set untuk ujian lanjut.
Latih Model Bahasa ASR anda
Lebih banyak maklumat set data anda, lebih baik prestasi model terlatih AI anda. Oleh itu, hasilkan pelbagai variasi teks dan ucapan yang anda rakamkan sebelum ini. Parafrasa ayat yang sama menggunakan tatatanda pertuturan yang berbeza.
Nilaikan Output dan Akhir sekali, Lelaran
Akhir sekali, ukur output model ASR anda untuk menetapkan prestasinya. Uji model terhadap set ujian untuk menentukan kecekapannya. Sesuai, libatkan model ASR anda dalam gelung maklum balas untuk menjana output yang diingini dan membetulkan sebarang jurang.
[Baca juga: Gambaran Keseluruhan Komprehensif Pengecaman Pertuturan Automatik]

Apakah Kes Penggunaan Berbeza Pengecaman Pertuturan?
Teknologi pengecaman pertuturan sangat berleluasa dalam banyak industri hari ini. Beberapa industri yang menggunakan teknologi hebat ini adalah seperti berikut:
 Industri Makanan: Gergasi makanan seperti Wendy's dan McDonald's bersedia untuk meningkatkan pengalaman pelanggan mereka menggunakan ASR. Di kebanyakan cawangan mereka, mereka telah menggunakan model ASR yang berfungsi sepenuhnya untuk menerima tempahan, dan seterusnya menyerahkannya ke bahagian memasak untuk menyediakan pesanan pelanggan.
Industri Makanan: Gergasi makanan seperti Wendy's dan McDonald's bersedia untuk meningkatkan pengalaman pelanggan mereka menggunakan ASR. Di kebanyakan cawangan mereka, mereka telah menggunakan model ASR yang berfungsi sepenuhnya untuk menerima tempahan, dan seterusnya menyerahkannya ke bahagian memasak untuk menyediakan pesanan pelanggan.- Telekomunikasi: Vodafone adalah salah satu penyedia telekomunikasi terbesar di dunia. Ia telah mereka bentuk perkhidmatan penjagaan pelanggan dan penyampaian telefonnya dengan memanfaatkan model ASR yang membimbing anda menyelesaikan pertanyaan berbeza dan mengarahkan semula panggilan anda ke jabatan berkenaan.
- Perjalanan dan Pengangkutan: Google Android Auto atau Apple CarPlay telah menjadi perkara biasa. Kebanyakan orang menggunakannya untuk mengaktifkan sistem navigasi, menghantar mesej atau menukar senarai main muzik. Walau bagaimanapun, dengan kemajuan teknologi, sistem sedemikian menjadi lebih halus.
Pembantu Peribadi Pintar BMW yang dilancarkan dalam BMW 3 Series jauh lebih pintar daripada pembantu suara biasa. Ia boleh membolehkan pemandu mencari maklumat berkaitan kereta dan mengendalikan kereta menggunakan arahan suara. - Media dan Hiburan: Industri media juga menggunakan ASR dalam kebanyakan projeknya. Youtube telah melancarkan pembantu berasaskan AI yang menjana kapsyen automatik secara langsung. Semasa anda bercakap pada skrin, pembantu akan menyediakan sari kata untuk menjadikan video itu boleh diakses oleh kumpulan pengguna Youtube yang lebih besar.
 Industri Makanan: Gergasi makanan seperti Wendy's dan McDonald's bersedia untuk meningkatkan pengalaman pelanggan mereka menggunakan ASR. Di kebanyakan cawangan mereka, mereka telah menggunakan model ASR yang berfungsi sepenuhnya untuk menerima tempahan, dan seterusnya menyerahkannya ke bahagian memasak untuk menyediakan pesanan pelanggan.
Industri Makanan: Gergasi makanan seperti Wendy's dan McDonald's bersedia untuk meningkatkan pengalaman pelanggan mereka menggunakan ASR. Di kebanyakan cawangan mereka, mereka telah menggunakan model ASR yang berfungsi sepenuhnya untuk menerima tempahan, dan seterusnya menyerahkannya ke bahagian memasak untuk menyediakan pesanan pelanggan. Telekomunikasi: Vodafone adalah salah satu penyedia telekomunikasi terbesar di dunia. Ia telah mereka bentuk perkhidmatan penjagaan pelanggan dan penyampaian telefonnya dengan memanfaatkan model ASR yang membimbing anda menyelesaikan pertanyaan berbeza dan mengarahkan semula panggilan anda ke jabatan berkenaan.
Telekomunikasi: Vodafone adalah salah satu penyedia telekomunikasi terbesar di dunia. Ia telah mereka bentuk perkhidmatan penjagaan pelanggan dan penyampaian telefonnya dengan memanfaatkan model ASR yang membimbing anda menyelesaikan pertanyaan berbeza dan mengarahkan semula panggilan anda ke jabatan berkenaan. Perjalanan dan Pengangkutan: Google Android Auto atau Apple CarPlay telah menjadi perkara biasa. Kebanyakan orang menggunakannya untuk mengaktifkan sistem navigasi, menghantar mesej atau menukar senarai main muzik. Walau bagaimanapun, dengan kemajuan teknologi, sistem sedemikian menjadi lebih halus.
Perjalanan dan Pengangkutan: Google Android Auto atau Apple CarPlay telah menjadi perkara biasa. Kebanyakan orang menggunakannya untuk mengaktifkan sistem navigasi, menghantar mesej atau menukar senarai main muzik. Walau bagaimanapun, dengan kemajuan teknologi, sistem sedemikian menjadi lebih halus. Media dan Hiburan: Industri media juga menggunakan ASR dalam kebanyakan projeknya. Youtube telah melancarkan pembantu berasaskan AI yang menjana kapsyen automatik secara langsung. Semasa anda bercakap pada skrin, pembantu akan menyediakan sari kata untuk menjadikan video itu boleh diakses oleh kumpulan pengguna Youtube yang lebih besar.
Media dan Hiburan: Industri media juga menggunakan ASR dalam kebanyakan projeknya. Youtube telah melancarkan pembantu berasaskan AI yang menjana kapsyen automatik secara langsung. Semasa anda bercakap pada skrin, pembantu akan menyediakan sari kata untuk menjadikan video itu boleh diakses oleh kumpulan pengguna Youtube yang lebih besar.
[Baca juga: Apakah Teknologi Ucapan-Ke-Teks dan Bagaimana Ia Berfungsi]
Bagaimanakah Shaip Boleh Membantu?
Shaip ialah salah satu perkhidmatan latihan AI terkemuka yang memegang kepakaran dalam pelbagai bidang AI dan ML. Mereka boleh membantu anda membina set data anda sendiri yang boleh digunakan untuk aplikasi dan projek yang berbeza.
Antara perkhidmatan yang disediakan oleh Shaip adalah:
- Pengecaman Pertuturan Automatik (ASR)
- Koleksi Ucapan Skrip
- Penciptaan
- Koleksi Ucapan Spontan
- Koleksi Lafaz/ Kata Bangun,
- Teks ke pertuturan (TTS)
Anda boleh memanfaatkan perkhidmatan ini untuk mendapatkan hasil terbaik untuk projek berasaskan AI anda. Ketahui lebih lanjut tentang perkhidmatan ini dengan menghubungi pasukan pakar kami hari ini!


