
Internet telah membuka pintu kepada orang ramai secara bebas menyatakan pendapat, pandangan dan cadangan mereka tentang apa sahaja di dunia mengenai media sosial, tapak web dan blog. Selain menyuarakan pendapat, orang ramai (pelanggan) juga turut mempengaruhi keputusan membeli orang lain. Sentimen, sama ada negatif atau positif, adalah kritikal untuk mana-mana perniagaan atau jenama yang mengambil berat tentang jualan produk atau perkhidmatannya.
Membantu perniagaan melombong ulasan untuk kegunaan perniagaan adalah Pemprosesan Bahasa Asli. Satu daripada setiap empat perniagaan mempunyai rancangan untuk melaksanakan teknologi NLP dalam tahun hadapan untuk memperkasakan keputusan perniagaan mereka. Menggunakan analisis sentimen, NLP membantu perniagaan memperoleh cerapan yang boleh ditafsir daripada data mentah dan tidak berstruktur.
Perlombongan pendapat atau analisis sentimen ialah teknik NLP yang digunakan untuk mengenal pasti sentimen yang tepat - positif, negatif atau neutral – dikaitkan dengan komen dan maklum balas. Dengan bantuan NLP, kata kunci dalam ulasan dianalisis untuk menentukan perkataan positif atau negatif yang terkandung dalam kata kunci.
Sentimen dijaringkan pada sistem penskalaan yang memberikan skor sentimen kepada emosi dalam sekeping teks (menentukan teks sebagai positif atau negatif).
Apakah Analisis Sentimen Berbilang Bahasa?

Seperti namanya, analisis sentimen berbilang bahasa ialah teknik melaksanakan skor sentimen untuk lebih daripada satu bahasa. Walau bagaimanapun, ia tidak semudah itu. Budaya, bahasa dan pengalaman kita sangat mempengaruhi tingkah laku dan emosi pembelian kita. Tanpa pemahaman yang baik tentang bahasa, konteks dan budaya pengguna, adalah mustahil untuk memahami niat, emosi dan tafsiran pengguna dengan tepat.
Walaupun automasi adalah jawapan kepada banyak masalah zaman moden kita, terjemahan mesin perisian tidak akan dapat mengambil nuansa bahasa, bahasa sehari-hari, kehalusan, dan rujukan budaya dalam ulasan dan ulasan produk ia sedang menterjemah. Alat ML mungkin memberi anda terjemahan, tetapi ia mungkin tidak berguna. Itulah sebab mengapa analisis sentimen berbilang bahasa diperlukan.
Mengapa Analisis Sentimen Pelbagai Bahasa Diperlukan?
Kebanyakan perniagaan menggunakan bahasa Inggeris sebagai medium komunikasi mereka, tetapi ia tidak digunakan oleh kebanyakan pengguna di seluruh dunia.
Menurut Ethnologue, kira-kira 13% penduduk dunia berbahasa Inggeris. Selain itu, British Council menyatakan bahawa kira-kira 25% penduduk dunia mempunyai pemahaman yang baik tentang bahasa Inggeris. Jika nombor ini boleh dipercayai, maka sebahagian besar pengguna berinteraksi antara satu sama lain dan perniagaan dalam bahasa selain bahasa Inggeris.
Jika matlamat utama perniagaan adalah untuk memastikan asas pelanggan mereka utuh dan menarik pelanggan baharu, ia perlu memahami secara mendalam pendapat pelanggan mereka yang dinyatakan dalam mereka. Bahasa asal. Menyemak setiap ulasan secara manual atau menterjemahkannya ke dalam bahasa Inggeris adalah proses yang menyusahkan yang tidak akan membuahkan hasil yang berkesan.
Penyelesaian yang mampan ialah membangunkan pelbagai bahasa sistem analisis sentimen yang mengesan dan menganalisis pendapat, emosi dan cadangan pelanggan dalam media sosial, forum, tinjauan dan banyak lagi.
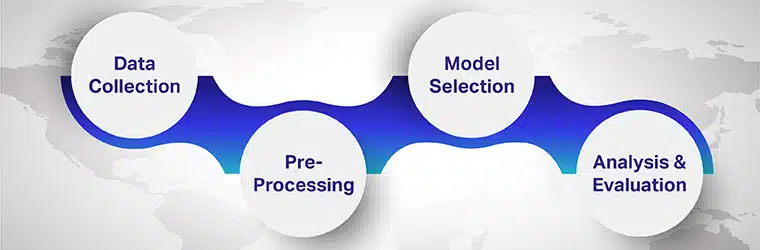
Langkah-langkah untuk melakukan Analisis Sentimen Pelbagai Bahasa
Analisis sentimen, tidak kira sama ada dalam satu bahasa atau pelbagai bahasa, ialah proses yang memerlukan aplikasi model pembelajaran mesin, pemprosesan bahasa semula jadi dan teknik analisis data untuk mengekstrak pemarkahan sentimen berbilang bahasa daripada data.
Langkah-langkah yang terlibat dalam analisis sentimen berbilang bahasa ialah
Langkah 1: Mengumpul Data
Mengumpul data adalah langkah pertama dalam menggunakan analisis sentimen. Untuk mencipta pelbagai bahasa model analisis sentimen, adalah penting untuk memperoleh data dalam pelbagai bahasa. Segala-galanya akan bergantung pada kualiti data yang dikumpul, dianotasi dan dilabelkan. Anda boleh menarik data daripada API, repositori sumber terbuka dan penerbit.
Langkah 2: Pra-pemprosesan
Data web yang dikumpul harus dibersihkan, dan maklumat diperoleh daripadanya. Bahagian teks yang tidak membawa maksud tertentu, seperti 'the' 'is' dan banyak lagi, harus dialih keluar. Seterusnya, teks hendaklah dikelompokkan kepada kumpulan kata untuk dikategorikan bagi menyampaikan maksud positif atau negatif.
Untuk meningkatkan kualiti klasifikasi, kandungan harus dibersihkan daripada hingar, seperti teg HTML, iklan dan skrip. Bahasa, leksikon dan tatabahasa yang digunakan oleh orang adalah berbeza bergantung pada rangkaian sosial. Adalah penting untuk menormalkan kandungan tersebut dan menyediakannya untuk pra-pemprosesan.
Satu lagi langkah kritikal dalam prapemprosesan ialah menggunakan pemprosesan bahasa semula jadi untuk memecah ayat, mengalih keluar perkataan henti, menandai bahagian pertuturan, mengubah perkataan menjadi bentuk akarnya dan menjadikan perkataan sebagai simbol dan teks.
Langkah 3: Pemilihan Model
Model berasaskan peraturan: Kaedah analisis semantik berbilang bahasa yang paling mudah adalah berasaskan peraturan. Algoritma berasaskan peraturan melaksanakan analisis berdasarkan set peraturan yang telah ditetapkan yang diprogramkan oleh pakar.
Peraturan itu boleh menentukan perkataan atau frasa yang positif atau negatif. Jika anda mengambil ulasan produk atau perkhidmatan, sebagai contoh, ia mungkin mengandungi perkataan positif atau negatif seperti 'hebat,' 'lambat', 'tunggu' dan 'berguna.' Kaedah ini memudahkan untuk mengklasifikasikan perkataan, tetapi ia boleh salah mengklasifikasikan perkataan yang rumit atau kurang kerap.
Model Automatik: Model automatik melakukan analisis sentimen berbilang bahasa tanpa penglibatan penyederhana manusia. Walaupun model pembelajaran mesin dibina menggunakan usaha manusia, ia boleh berfungsi secara automatik untuk menyampaikan hasil yang tepat sebaik sahaja dibangunkan.
Data ujian dianalisis, dan setiap ulasan dilabelkan secara manual sebagai positif atau negatif. Model ML kemudiannya akan belajar daripada data ujian dengan membandingkan teks baharu dengan ulasan sedia ada dan mengkategorikannya.
Langkah 4: Analisis dan Penilaian
Model berasaskan peraturan dan pembelajaran mesin boleh dipertingkatkan dan dipertingkatkan dari semasa ke semasa dan pengalaman. Leksikon perkataan yang kurang kerap digunakan atau skor langsung untuk sentimen berbilang bahasa boleh dikemas kini untuk pengelasan yang lebih pantas dan tepat.
Cabaran Penterjemahan
Tidak cukupkah terjemahan? Sebenarnya tidak!
Terjemahan melibatkan pemindahan teks atau kumpulan teks daripada satu bahasa dan mencari persamaan dalam bahasa lain. Walau bagaimanapun, terjemahan tidak mudah dan tidak berkesan.
Itu kerana manusia menggunakan bahasa bukan sahaja untuk menyampaikan keperluan mereka tetapi juga untuk meluahkan emosi mereka. Selain itu, terdapat perbezaan ketara antara bahasa yang berbeza, seperti bahasa Inggeris, Hindi, Mandarin dan Thai. Tambahkan pada campuran sastera ini penggunaan emosi, slanga, simpulan bahasa, sindiran dan emoji. Tidak mungkin untuk mendapatkan terjemahan teks yang tepat.
Beberapa cabaran utama terjemahan mesin adalah
- Subjektiviti
- Konteks
- Slang dan Idiom
- Sarkasme
- Perbandingan
- Berkecuali
- Emoji dan Penggunaan perkataan Moden.
Tanpa memahami dengan tepat maksud yang dimaksudkan ulasan, ulasan dan komunikasi berkenaan produk, harga, perkhidmatan, ciri dan kualiti mereka, perniagaan tidak akan dapat memahami keperluan dan pendapat pelanggan.
Analisis sentimen pelbagai bahasa adalah proses yang mencabar. Setiap bahasa mempunyai leksikon, sintaksis, morfologi dan fonologi yang unik. Tambahkan pada ini budaya, slanga, sentimen yang diluahkan, sindiran dan nada suara, dan anda mempunyai teka-teki mencabar yang memerlukan penyelesaian ML berkuasa AI yang cekap.
Set data berbilang bahasa yang komprehensif diperlukan untuk membangunkan pelbagai bahasa yang mantap alat analisis sentimen yang boleh memproses ulasan dan memberikan cerapan yang kuat kepada perniagaan. Shaip ialah peneraju pasaran dalam menyediakan set data beranotasi, berlabel dan disesuaikan industri dalam beberapa bahasa yang membantu dalam membangunkan cekap dan tepat penyelesaian analisis sentimen berbilang bahasa.


