
Data ialah kuasa besar yang mengubah landskap digital di dunia hari ini. Dari e-mel ke siaran media sosial, terdapat data di mana-mana. Memang benar bahawa perniagaan tidak pernah mempunyai akses kepada begitu banyak data, tetapi adakah mempunyai akses kepada data mencukupi? Sumber maklumat yang kaya menjadi tidak berguna atau usang apabila ia tidak diproses.
Teks tidak berstruktur boleh menjadi sumber maklumat yang kaya, tetapi ia tidak akan berguna kepada perniagaan melainkan data itu disusun, dikategorikan dan dianalisis. Data tidak berstruktur, seperti teks, audio, video dan media sosial, berjumlah 80 -90% daripada semua data. Selain itu, hampir 18% organisasi dilaporkan mengambil kesempatan daripada data tidak berstruktur organisasi mereka.
Menapis secara manual melalui terabait data yang disimpan dalam pelayan adalah tugas yang memakan masa dan sejujurnya mustahil. Walau bagaimanapun, dengan kemajuan dalam pembelajaran mesin, pemprosesan bahasa semula jadi dan automasi, adalah mungkin untuk menstruktur dan menganalisis data teks dengan cepat dan berkesan. Langkah pertama dalam analisis data ialah klasifikasi teks.
Apakah Klasifikasi Teks?
Pengelasan atau pengkategorian teks ialah proses mengumpulkan teks ke dalam kategori atau kelas yang telah ditetapkan. Menggunakan pendekatan pembelajaran mesin ini, mana-mana teks – dokumen, fail web, kajian, dokumen undang-undang, laporan perubatan dan banyak lagi – boleh dikelaskan, tersusun dan berstruktur.
Pengelasan teks ialah langkah asas dalam pemprosesan bahasa semula jadi yang mempunyai beberapa kegunaan dalam pengesanan spam. Analisis sentimen, pengesanan niat, pelabelan data dan banyak lagi.
Kemungkinan Kes Penggunaan Klasifikasi Teks
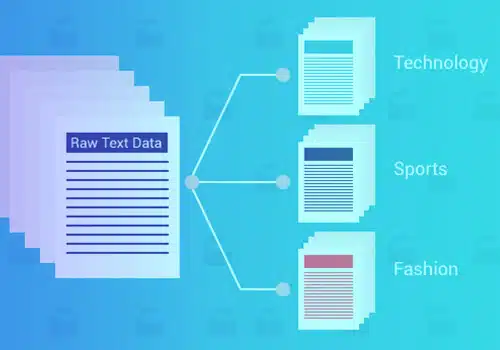 Terdapat beberapa faedah menggunakan klasifikasi teks pembelajaran mesin, seperti kebolehskalaan, kelajuan analisis, konsistensi dan keupayaan untuk membuat keputusan pantas berdasarkan perbualan masa nyata.
Terdapat beberapa faedah menggunakan klasifikasi teks pembelajaran mesin, seperti kebolehskalaan, kelajuan analisis, konsistensi dan keupayaan untuk membuat keputusan pantas berdasarkan perbualan masa nyata.
Apabila model ML dilatih menggunakan AI yang secara automatik mengkategorikan item di bawah kategori yang telah ditetapkan, anda boleh menukar penyemak imbas kasual dengan cepat kepada pelanggan.
Proses Pengelasan Teks
Proses pengelasan teks bermula dengan pra-pemprosesan, pemilihan ciri, pengekstrakan dan pengelasan data.

Pra-Pemprosesan
Tokenisasi: Teks dipecahkan kepada bentuk teks yang lebih kecil dan ringkas untuk pengelasan mudah.
Normalisasi: Semua teks dalam dokumen perlu berada pada tahap kefahaman yang sama. Beberapa bentuk normalisasi termasuk,
- Mengekalkan standard tatabahasa atau struktur merentas teks, seperti mengalih keluar ruang putih atau tanda baca. Atau mengekalkan huruf kecil di seluruh teks.
- Mengalih keluar awalan dan akhiran daripada perkataan dan membawanya kembali kepada kata dasarnya.
- Mengalih keluar perkataan henti seperti 'dan' 'adalah' 'the' dan banyak lagi yang tidak menambah nilai pada teks.
Pemilihan Ciri
Pemilihan ciri ialah langkah asas dalam pengelasan teks. Proses ini bertujuan untuk mewakili teks dengan ciri yang paling relevan. Pilihan ciri membantu mengalih keluar data yang tidak berkaitan dan meningkatkan ketepatan.
Pemilihan ciri mengurangkan pembolehubah input ke dalam model dengan hanya menggunakan data yang paling relevan dan menghapuskan hingar. Berdasarkan jenis penyelesaian yang anda cari, model AI anda boleh direka bentuk untuk memilih ciri yang berkaitan sahaja daripada teks.
Pengekstrakan Ciri
Pengekstrakan ciri ialah langkah pilihan yang diambil oleh sesetengah perniagaan untuk mengekstrak ciri utama tambahan dalam data. Pengekstrakan ciri menggunakan beberapa teknik, seperti pemetaan, penapisan dan pengelompokan. Faedah utama menggunakan pengekstrakan ciri ialah – ia membantu mengalih keluar data berlebihan dan meningkatkan kelajuan model ML dibangunkan.
Menandai Data kepada Kategori yang Ditetapkan
Menandai teks kepada kategori yang dipratentukan ialah langkah terakhir dalam pengelasan teks. Ia boleh dilakukan dalam tiga cara yang berbeza,
- Penandaan Manual
- Padanan Berasaskan Peraturan
- Algoritma Pembelajaran – Algoritma pembelajaran selanjutnya boleh diklasifikasikan kepada dua kategori seperti pengetegan diselia dan pengetegan tanpa penyeliaan.
- Pembelajaran diselia: Model ML boleh menjajarkan teg secara automatik dengan data terkategori sedia ada dalam pengetegan diselia. Apabila data yang dikategorikan sudah tersedia, algoritma ML boleh memetakan fungsi antara teg dan teks.
- Pembelajaran tanpa seliaan: Ia berlaku apabila terdapat kekurangan data teg sedia ada sebelum ini. Model ML menggunakan algoritma pengelompokan dan berasaskan peraturan untuk mengumpulkan teks yang serupa, seperti berdasarkan sejarah pembelian produk, ulasan, butiran peribadi dan tiket. Kumpulan luas ini boleh dianalisis lebih lanjut untuk mendapatkan cerapan khusus pelanggan yang berharga yang boleh digunakan untuk mereka bentuk pendekatan pelanggan yang disesuaikan.
Terdapat berbilang kes penggunaan untuk klasifikasi teks merentas industri. Walaupun pengumpulan, pengelompokan, pengelasan dan pengekstrakan cerapan berharga daripada data teks sentiasa digunakan dalam beberapa bidang, pengelasan teks mencari potensinya dalam pemasaran, pembangunan produk, perkhidmatan pelanggan, pengurusan dan pentadbiran. Ia membantu perniagaan memperoleh kecerdasan kompetitif, pengetahuan pasaran dan pelanggan, serta membuat keputusan perniagaan yang disokong data.
Membangunkan alat pengelasan teks yang berkesan dan berwawasan bukanlah mudah. Namun, dengan Shaip sebagai rakan kongsi data anda, anda boleh membangunkan alat klasifikasi teks berasaskan AI yang berkesan, berskala dan kos efektif. Kami mempunyai banyak set data beranotasi dengan tepat dan sedia untuk digunakan yang boleh disesuaikan untuk keperluan unik model anda. Kami menukar teks anda menjadi kelebihan daya saing; hubungi hari ini.


