
Pernahkah anda terfikir bagaimana chatbots dan pembantu maya bangun apabila anda berkata, 'Hei Siri' atau 'Alexa'? Ia adalah kerana pengumpulan ujaran teks atau mencetuskan perkataan yang tertanam dalam perisian yang mengaktifkan sistem sebaik sahaja ia mendengar perkataan bangun yang diprogramkan.
Walau bagaimanapun, proses keseluruhan untuk mencipta bunyi dan data sebutan tidaklah semudah itu. Ia adalah satu proses yang mesti dijalankan dengan teknik yang betul untuk mendapatkan hasil yang diinginkan. Oleh itu, blog ini akan berkongsi laluan untuk mencipta ujaran/perkataan pencetus yang baik yang berfungsi dengan lancar dengan AI perbualan anda.
Apakah Ujaran?
Ujaran boleh dirujuk sebagai frasa atau perkataan pencetus yang digunakan untuk mengaktifkan model pintar buatan. Apabila model AI anda mengesan perkataan bangunnya, ia mula merakam permintaan seterusnya pengguna secara automatik dan membalas dengan tindakan atau balasan yang sesuai.
Utterance menggunakan konsep pembelajaran mendalam untuk mengajar perisian cara mengenali perkataan bangun. Sebaik sahaja wake word mengaktifkan perisian, sistem mula menangkap, menyahkod dan melayan permintaan. Apabila tidak digunakan, sistem secara pasif terus mendengar perkataan pencetus.
Untuk perisian AI anda memperoleh hasil yang tepat, menangkap banyak sebutan yang berbeza untuk setiap niat adalah penting. Ia membantu dalam latihan yang lebih baik untuk model AI.
[Baca juga: Adakah anda ingin tahu bagaimana Siri dan Alexa Memahami Anda?]
Perkara yang Perlu Diingati Semasa Mencipta Repositori Ujaran
Sekarang setelah kita tahu bahawa latihan adalah penting untuk model AI, perkara seterusnya yang perlu diketahui ialah cara memberikan sebutan kepada model AI. Biasanya, repositori ujaran dicipta untuk melatih AI perbualan.
Walau bagaimanapun, terdapat pelbagai perkara yang perlu diingat semasa membina repositori ujaran. Berikut adalah perkara yang perlu dipertimbangkan:
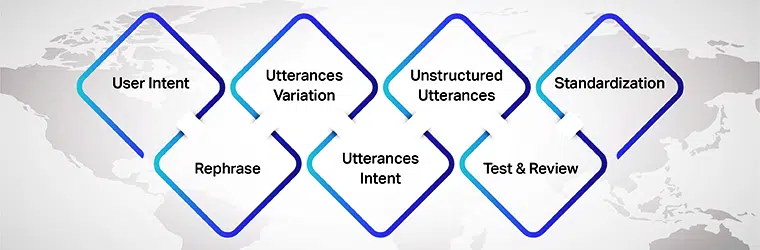
Niat Pengguna
Terutamanya semasa menyediakan sebutan untuk model AI anda, pastikan anda memahami niat pengguna yang anda bangunkan set data. Anda perlu memikirkan sebutan berbeza yang mungkin dimasukkan oleh pengguna semasa bercakap dengan model AI.
Variasi Lafaz
Variasi adalah bahagian penting dalam proses ini, kerana lebih banyak variasi untuk setiap niat, lebih baik hasil yang akan anda capai. Jadi, pastikan anda mencipta pelbagai variasi ujaran pengguna. Anda boleh melakukannya dengan
- Mencipta ayat pendek, sederhana dan besar untuk ayat yang sama.
- Mengubah perkataan dan panjang ayat.
- Menggunakan perkataan yang unik.
- Pemajmukan ayat.
- Mencampur adukkan tatabahasa.



