






Pengumpulan Teks

Koleksi Audio / Ucapan
Anotasi Teks
Anotasi Audio / Ucapan

Transkripsi Teks

Transkripsi Audio / Ucapan




Latihan AI / Chatbot Perbualan
Melatih pembantu digital memerlukan sebilangan besar data berkualiti dari pelbagai geografi, bahasa, dialek, susunan, dan format. Di Shaip, kami menawarkan data latihan untuk Model AI dengan Human-in-the-loop yang mempunyai pengetahuan yang diperlukan, kepakaran domain, dan mengetahui keperluan khusus pelanggan.
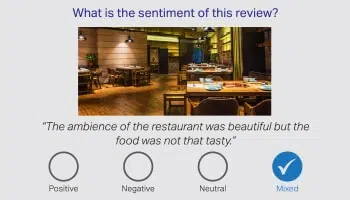
Sentimen / Niat
Analisis
Benar dikatakan, bahawa kata-kata sahaja gagal menyampaikan keseluruhan cerita, dan tanggungjawab terletak pada anotator manusia untuk menafsirkan kekaburan dalam bahasa manusia. Oleh itu, mengenal pasti Sentimen pelanggan, berdasarkan perbualan adalah sangat penting. Pakar bahasa kami dari pelbagai domain dapat menafsirkan nuansa dalam ulasan produk, berita kewangan, dan media sosial.

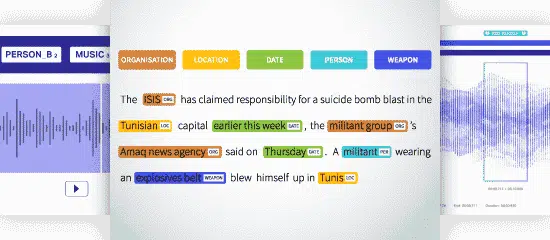
Pengiktirafan Entiti Dinamakan (NER)
Named Entity Recognition (NER) adalah mengenal pasti, mengekstrak, dan mengklasifikasikan entiti yang dinamakan dalam teks, ke dalam kategori yang telah ditentukan. Teks tersebut dapat dikategorikan sebagai tempat, nama, organisasi, produk, kuantiti, nilai, peratusan, dan lain-lain. Dengan NER, Anda dapat menjawab pertanyaan di dunia nyata seperti organisasi mana yang disebutkan dalam artikel itu dll.
Automasi Perkhidmatan Pelanggan
Virtual Chatbots atau Pembantu Digital yang kuat dan terlatih telah merevolusikan cara pelanggan berkomunikasi dengan penjual menambah peningkatan pengalaman pelanggan yang ketara.

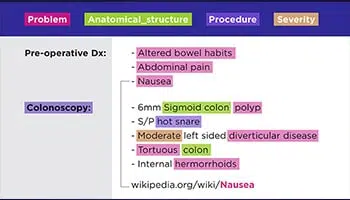
Transkripsi Teks
Dari preskripsi tulisan tangan doktor hingga nota panggilan persidangan, pakar kami dapat mendigitalkan sebarang bentuk data seperti, dokumen yang diarkibkan, kontrak undang-undang, rekod kesihatan pesakit, dll.
Pengkategorian Kandungan
Pengkategorian yang juga dikenali sebagai klasifikasi atau penandaan adalah proses mengklasifikasikan teks ke dalam kumpulan teratur dan melabelnya, berdasarkan ciri-ciri minatnya.

Analisis Topik
Analisis Topik atau pelabelan topik adalah mengenal pasti dan mengekstrak makna dari teks yang diberikan dengan mengenal pasti topik / tema berulang yang sedang dipertimbangkan.

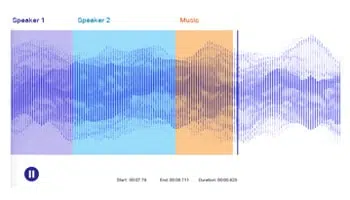
Transkripsi Audio
Transkripsikan ucapan / podcast / seminar, panggil perbualan ke dalam teks. Manfaatkan manusia untuk memberi anotasi fail audio / pertuturan dengan tepat untuk melatih model NLP dengan tepat.

Pengelasan Audio
Kategorikan bunyi atau ujaran untuk mengklasifikasikan pertuturan / audio berdasarkan bahasa, dialek, semantik, leksikon, dll.

orang
Pasukan yang berdedikasi dan terlatih:
- 30,000+ kolaborator untuk Pembuatan Data, Pelabelan & QA
- Pasukan Pengurusan Projek yang diperakui
- Pasukan Pembangunan Produk yang berpengalaman
- Pasukan Penyediaan Bakat & Pasukan Bakat

Proses
Kecekapan proses tertinggi dijamin dengan:
- Proses Gerbang Tahap Sigma 6 yang kuat
- Pasukan khusus 6 tali pinggang hitam Sigma - Pemilik proses utama & Pematuhan kualiti
- Gelung Penambahbaikan & Maklum Balas yang Berterusan

platform
Platform yang dipatenkan menawarkan faedah:
- Platform hujung ke hujung berasaskan web
- Kualiti yang sempurna
- TAT lebih pantas
- Penghantaran lancar


