

Apakah Model Bahasa Besar?
Model Bahasa Besar (LLM) ialah sistem kecerdasan buatan (AI) lanjutan yang direka untuk memproses, memahami dan menjana teks seperti manusia. Ia berdasarkan teknik pembelajaran mendalam dan dilatih pada set data besar-besaran, biasanya mengandungi berbilion perkataan daripada pelbagai sumber seperti tapak web, buku dan artikel. Latihan yang meluas ini membolehkan LLM memahami nuansa bahasa, tatabahasa, konteks, dan juga beberapa aspek pengetahuan am.
Beberapa LLM yang popular, seperti GPT-3 OpenAI, menggunakan sejenis rangkaian saraf yang dipanggil pengubah, yang membolehkan mereka mengendalikan tugas bahasa yang kompleks dengan kecekapan yang luar biasa. Model ini boleh melakukan pelbagai tugas, seperti:
- Menjawab soalan
- Merumuskan teks
- Menterjemahkan bahasa
- Menjana kandungan
- Malah melibatkan diri dalam perbualan interaktif dengan pengguna
Apabila LLM terus berkembang, mereka mempunyai potensi besar untuk mempertingkat dan mengautomasikan pelbagai aplikasi merentas industri, daripada perkhidmatan pelanggan dan penciptaan kandungan kepada pendidikan dan penyelidikan. Walau bagaimanapun, mereka juga menimbulkan kebimbangan etika dan masyarakat, seperti tingkah laku berat sebelah atau penyalahgunaan, yang perlu ditangani seiring dengan kemajuan teknologi.

Contoh Popular Model Bahasa Besar
Berikut ialah beberapa contoh utama LLM yang digunakan secara meluas dalam menegak industri yang berbeza:
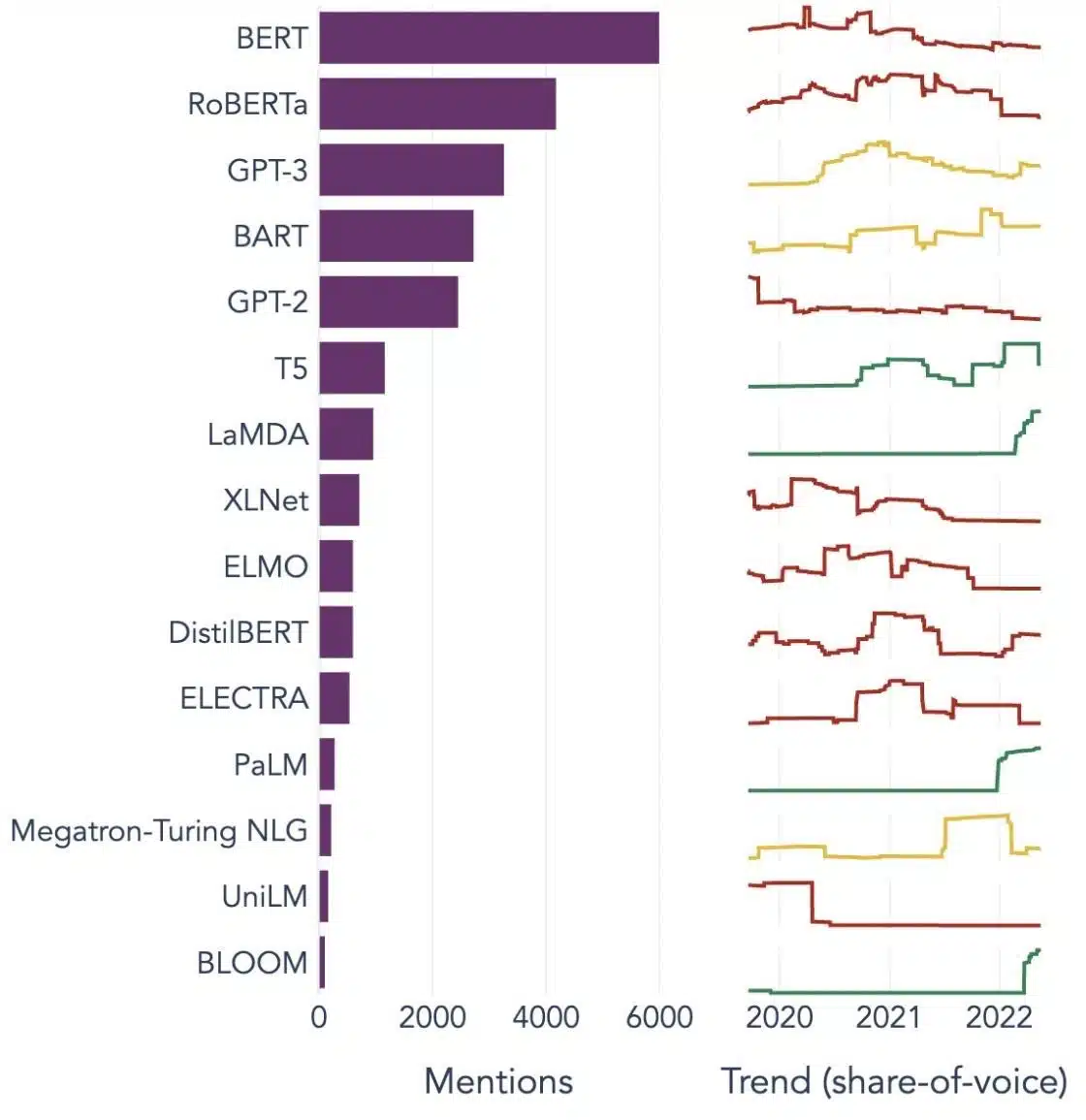
Imej Source: Ke arah Sains data
Bagaimanakah model LLM dilatih?
Melatih model bahasa besar (LLM) adalah satu kejayaan yang melibatkan beberapa langkah penting. Berikut ialah ringkasan langkah demi langkah proses yang dipermudahkan:
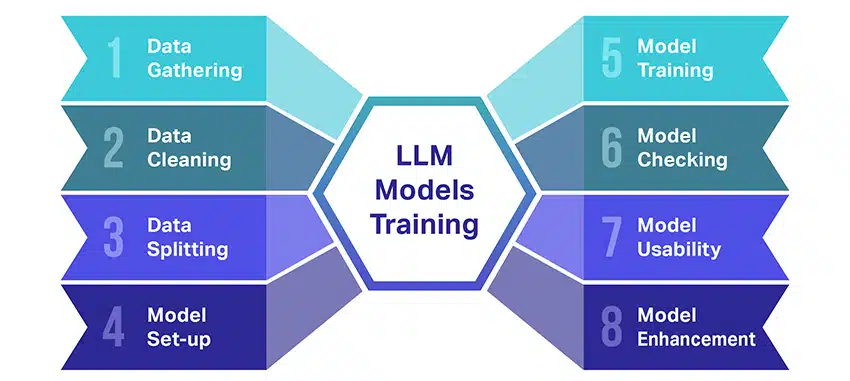
- Mengumpul Data Teks: Latihan LLM bermula dengan pengumpulan sejumlah besar data teks. Data ini boleh datang daripada buku, tapak web, artikel atau platform media sosial. Matlamatnya adalah untuk menangkap kepelbagaian bahasa manusia yang kaya.
- Membersihkan Data: Data teks mentah kemudiannya dikemaskan dalam proses yang dipanggil prapemprosesan. Ini termasuk tugas seperti mengalih keluar aksara yang tidak diingini, memecahkan teks kepada bahagian yang lebih kecil yang dipanggil token dan memasukkan semuanya ke dalam format yang boleh digunakan oleh model.
- Membahagikan Data: Seterusnya, data bersih dibahagikan kepada dua set. Satu set, data latihan, akan digunakan untuk melatih model. Set lain, data pengesahan, akan digunakan kemudian untuk menguji prestasi model.
- Menyediakan Model: Struktur LLM, yang dikenali sebagai seni bina, kemudiannya ditakrifkan. Ini melibatkan pemilihan jenis rangkaian saraf dan memutuskan pelbagai parameter, seperti bilangan lapisan dan unit tersembunyi dalam rangkaian.
- Melatih Model: Latihan sebenar kini bermula. Model LLM belajar dengan melihat data latihan, membuat ramalan berdasarkan perkara yang telah dipelajari setakat ini, dan kemudian melaraskan parameter dalamannya untuk mengurangkan perbezaan antara ramalannya dan data sebenar.
- Menyemak Model: Pembelajaran model LLM disemak menggunakan data pengesahan. Ini membantu untuk melihat prestasi model dan untuk mengubah suai tetapan model untuk prestasi yang lebih baik.
- Menggunakan Model: Selepas latihan dan penilaian, model LLM sedia untuk digunakan. Ia kini boleh disepadukan ke dalam aplikasi atau sistem di mana ia akan menjana teks berdasarkan input baharu yang diberikannya.
- Memperbaiki Model: Akhirnya, sentiasa ada ruang untuk penambahbaikan. Model LLM boleh diperhalusi lagi dari semasa ke semasa, menggunakan data yang dikemas kini atau melaraskan tetapan berdasarkan maklum balas dan penggunaan dunia sebenar.
Ingat, proses ini memerlukan sumber pengiraan yang ketara, seperti unit pemprosesan yang berkuasa dan storan besar, serta pengetahuan khusus dalam pembelajaran mesin. Itulah sebabnya ia biasanya dilakukan oleh organisasi penyelidikan khusus atau syarikat yang mempunyai akses kepada infrastruktur dan kepakaran yang diperlukan.
Adakah LLM Bergantung pada Pembelajaran Diselia atau Tanpa Diawasi?
Model bahasa besar biasanya dilatih menggunakan kaedah yang dipanggil pembelajaran diselia. Secara ringkas, ini bermakna mereka belajar daripada contoh yang menunjukkan kepada mereka jawapan yang betul.
 Bayangkan anda sedang mengajar kanak-kanak perkataan dengan menunjukkan gambar kepada mereka. Anda menunjukkan kepada mereka gambar kucing dan menyebut "kucing", dan mereka belajar untuk mengaitkan gambar itu dengan perkataan itu. Begitulah cara pembelajaran yang diselia berfungsi. Model diberikan banyak teks ("gambar") dan output yang sepadan ("perkataan"), dan ia belajar untuk memadankannya.
Bayangkan anda sedang mengajar kanak-kanak perkataan dengan menunjukkan gambar kepada mereka. Anda menunjukkan kepada mereka gambar kucing dan menyebut "kucing", dan mereka belajar untuk mengaitkan gambar itu dengan perkataan itu. Begitulah cara pembelajaran yang diselia berfungsi. Model diberikan banyak teks ("gambar") dan output yang sepadan ("perkataan"), dan ia belajar untuk memadankannya.
Jadi, jika anda memberi LLM satu ayat, ia cuba meramalkan perkataan atau frasa seterusnya berdasarkan perkara yang telah dipelajari daripada contoh. Dengan cara ini, ia belajar cara menjana teks yang masuk akal dan sesuai dengan konteks.
Walau bagaimanapun, kadangkala LLM juga menggunakan sedikit pembelajaran tanpa pengawasan. Ini seperti membiarkan kanak-kanak meneroka bilik yang penuh dengan mainan yang berbeza dan belajar tentang mereka sendiri. Model melihat data tidak berlabel, corak pembelajaran dan struktur tanpa diberitahu jawapan yang "betul".
Pembelajaran diselia menggunakan data yang telah dilabelkan dengan input dan output, berbeza dengan pembelajaran tanpa seliaan, yang tidak menggunakan data output berlabel.
Secara ringkasnya, LLM terutamanya dilatih menggunakan pembelajaran terselia, tetapi mereka juga boleh menggunakan pembelajaran tanpa seliaan untuk meningkatkan keupayaan mereka, seperti untuk analisis penerokaan dan pengurangan dimensi.
Apakah Isipadu Data (Dalam GB) yang Diperlukan Untuk Melatih Model Bahasa Besar?
Dunia kemungkinan untuk pengecaman data pertuturan dan aplikasi suara sangat besar, dan ia digunakan dalam beberapa industri untuk banyak aplikasi.
Melatih model bahasa yang besar bukanlah satu proses yang sesuai untuk semua, terutamanya apabila melibatkan data yang diperlukan. Ia bergantung kepada banyak perkara:
- Reka bentuk model.
- Apakah pekerjaan yang perlu dilakukan?
- Jenis data yang anda gunakan.
- Sejauh mana anda mahu ia berprestasi?
Walau bagaimanapun, latihan LLM biasanya memerlukan sejumlah besar data teks. Tetapi betapa besarnya kita bercakap tentang? Baiklah, fikir jauh melebihi gigabait (GB). Kami biasanya melihat pada terabait (TB) atau bahkan petabait (PB) data.
Pertimbangkan GPT-3, salah satu LLM terbesar di sekeliling. Ia dilatih pada 570 GB data teks. LLM yang lebih kecil mungkin memerlukan kurang – mungkin 10-20 GB atau bahkan 1 GB gigabait – tetapi masih banyak.

Tetapi ia bukan hanya mengenai saiz data. Kualiti juga penting. Data perlu bersih dan pelbagai untuk membantu model belajar dengan berkesan. Dan anda tidak boleh melupakan bahagian penting teka-teki yang lain, seperti kuasa pengkomputeran yang anda perlukan, algoritma yang anda gunakan untuk latihan dan persediaan perkakasan yang anda miliki. Semua faktor ini memainkan peranan besar dalam melatih LLM.
Kebangkitan Model Bahasa Besar: Mengapa Ia Penting
LLM bukan lagi sekadar konsep atau percubaan. Mereka semakin memainkan peranan penting dalam landskap digital kami. Tetapi mengapa ini berlaku? Apakah yang menjadikan LLM ini begitu penting? Mari kita mendalami beberapa faktor utama.
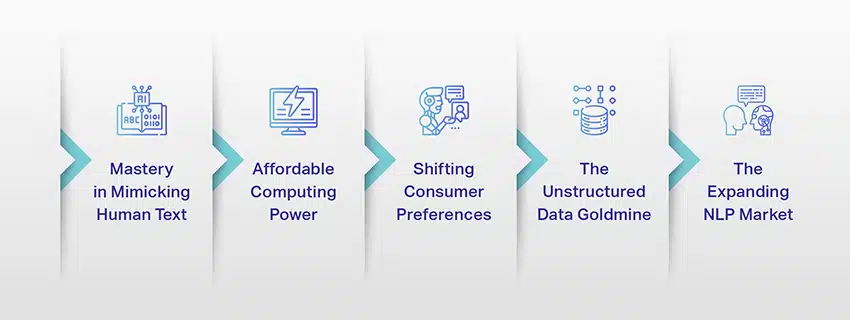
Penguasaan dalam Meniru Teks Manusia
LLM telah mengubah cara kami mengendalikan tugas berasaskan bahasa. Dibina menggunakan algoritma pembelajaran mesin yang mantap, model ini dilengkapi dengan keupayaan untuk memahami nuansa bahasa manusia, termasuk konteks, emosi, dan juga sindiran, sedikit sebanyak. Keupayaan untuk meniru bahasa manusia ini bukanlah sesuatu yang baru, ia mempunyai implikasi yang ketara.
Kebolehan penjanaan teks lanjutan LLM boleh meningkatkan segala-galanya daripada penciptaan kandungan kepada interaksi perkhidmatan pelanggan.
Bayangkan anda boleh bertanya soalan rumit kepada pembantu digital dan mendapat jawapan yang bukan sahaja masuk akal, tetapi juga koheren, relevan dan disampaikan dalam nada perbualan. Itulah yang didayakan oleh LLM. Mereka menyemarakkan interaksi mesin manusia yang lebih intuitif dan menarik, memperkayakan pengalaman pengguna dan mendemokrasikan akses kepada maklumat.
Kuasa Pengkomputeran Mampu Milik
Kebangkitan LLM tidak mungkin berlaku tanpa perkembangan selari dalam bidang pengkomputeran. Lebih khusus lagi, pendemokrasian sumber pengiraan telah memainkan peranan penting dalam evolusi dan penggunaan LLM.
Platform berasaskan awan menawarkan akses yang tidak pernah berlaku sebelum ini kepada sumber pengkomputeran berprestasi tinggi. Dengan cara ini, organisasi berskala kecil dan penyelidik bebas boleh melatih model pembelajaran mesin yang canggih.
Selain itu, penambahbaikan dalam unit pemprosesan (seperti GPU dan TPU), digabungkan dengan peningkatan pengkomputeran teragih, telah menjadikannya boleh dilaksanakan untuk melatih model dengan berbilion parameter. Peningkatan kebolehcapaian kuasa pengkomputeran ini membolehkan pertumbuhan dan kejayaan LLM, yang membawa kepada lebih banyak inovasi dan aplikasi dalam bidang ini.
Mengubah Keutamaan Pengguna
Pengguna hari ini bukan sahaja mahukan jawapan; mereka mahukan interaksi yang menarik dan boleh dikaitkan. Apabila semakin ramai orang membesar menggunakan teknologi digital, jelas sekali bahawa keperluan untuk teknologi yang dirasakan lebih semula jadi dan seperti manusia semakin meningkat. LLM menawarkan peluang yang tiada tandingan untuk memenuhi jangkaan ini. Dengan menjana teks seperti manusia, model ini boleh mencipta pengalaman digital yang menarik dan dinamik, yang boleh meningkatkan kepuasan dan kesetiaan pengguna. Sama ada chatbots AI yang menyediakan perkhidmatan pelanggan atau pembantu suara yang menyediakan kemas kini berita, LLM sedang memulakan era AI yang lebih memahami kita.
Lombong Emas Data Tidak Berstruktur
Data tidak berstruktur, seperti e-mel, siaran media sosial dan ulasan pelanggan, adalah harta karun cerapan. Dianggarkan sudah berakhir 80% data perusahaan tidak berstruktur dan berkembang pada kadar 55% setiap tahun. Data ini adalah lombong emas untuk perniagaan jika dimanfaatkan dengan betul.
LLM memainkan peranan di sini, dengan keupayaan mereka untuk memproses dan memahami data sedemikian pada skala. Mereka boleh mengendalikan tugas seperti analisis sentimen, klasifikasi teks, pengekstrakan maklumat dan banyak lagi, dengan itu memberikan cerapan berharga.
Sama ada mengenal pasti arah aliran daripada siaran media sosial atau mengukur sentimen pelanggan daripada ulasan, LLM membantu perniagaan menavigasi sejumlah besar data tidak berstruktur dan membuat keputusan berdasarkan data.
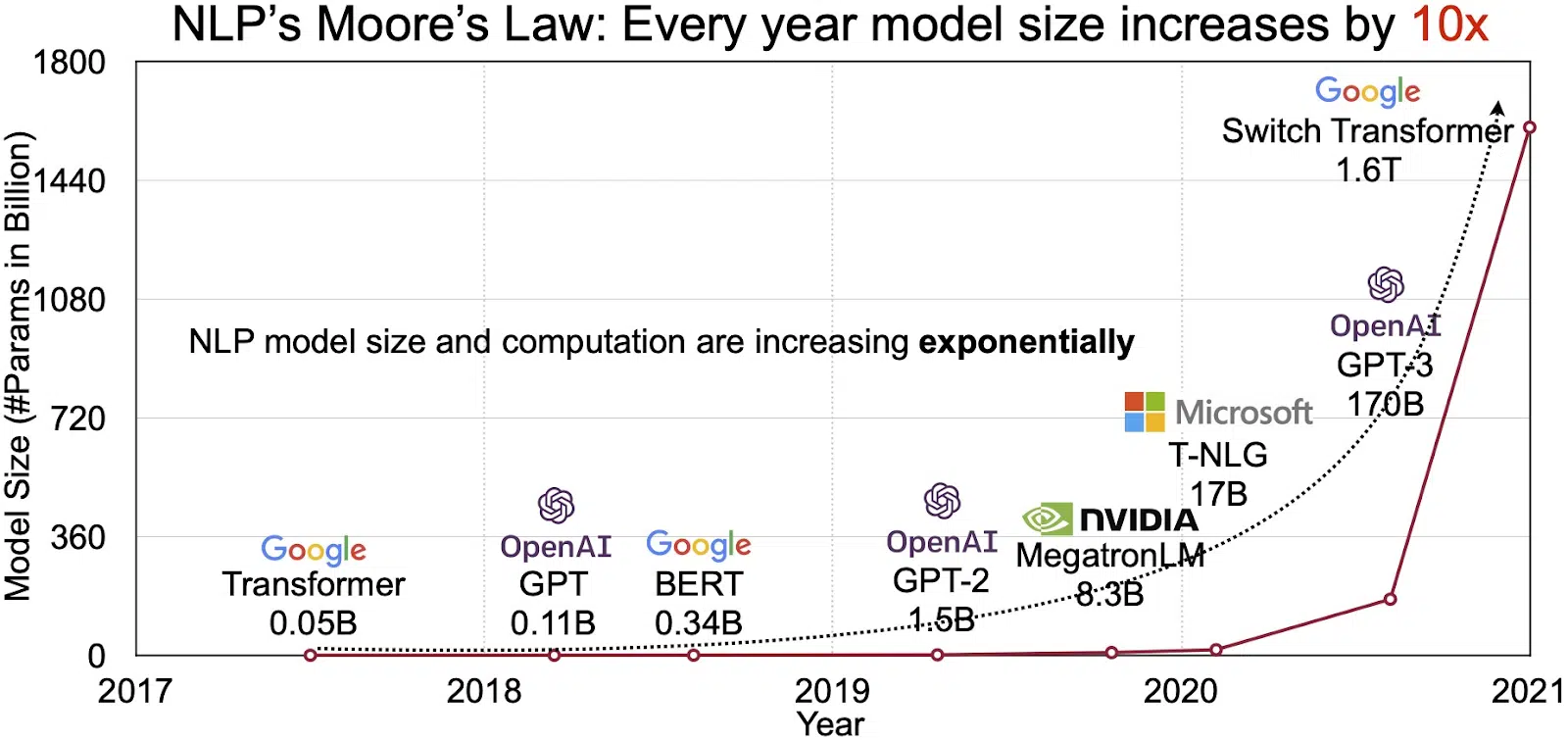
Pasaran NLP yang Berkembang
Potensi LLM dicerminkan dalam pasaran yang berkembang pesat untuk pemprosesan bahasa semula jadi (NLP). Penganalisis mengunjurkan pasaran NLP berkembang daripada $11 bilion pada 2020 kepada lebih $35 bilion menjelang 2026. Tetapi bukan hanya saiz pasaran yang berkembang. Model itu sendiri juga semakin berkembang, dalam saiz fizikal dan dalam bilangan parameter yang dikendalikannya. Evolusi LLM selama ini, seperti yang dilihat dalam rajah di bawah (sumber imej: pautan), menggariskan kerumitan dan kapasitinya yang semakin meningkat.
Kes Penggunaan Popular Model Bahasa Besar
Berikut ialah beberapa kes penggunaan LLM teratas dan paling lazim:
- Menjana Teks Bahasa Asli: Model Bahasa Besar (LLM) menggabungkan kuasa kecerdasan buatan dan linguistik pengiraan untuk menghasilkan teks secara autonomi dalam bahasa semula jadi. Mereka boleh memenuhi keperluan pengguna yang pelbagai seperti menulis artikel, mencipta lagu atau terlibat dalam perbualan dengan pengguna.
- Terjemahan melalui Mesin: LLM boleh digunakan dengan berkesan untuk menterjemah teks antara mana-mana pasangan bahasa. Model ini mengeksploitasi algoritma pembelajaran mendalam seperti rangkaian saraf berulang untuk memahami struktur linguistik kedua-dua bahasa sumber dan bahasa sasaran, dengan itu memudahkan terjemahan teks sumber ke dalam bahasa yang dikehendaki.
- Membuat Kandungan Asal: LLM telah membuka ruang untuk mesin menjana kandungan yang padu dan logik. Kandungan ini boleh digunakan untuk membuat catatan blog, artikel dan jenis kandungan lain. Model memanfaatkan pengalaman pembelajaran mendalam mereka yang mendalam untuk memformat dan menstruktur kandungan dalam cara yang baru dan mesra pengguna.
- Menganalisis Sentimen: Satu aplikasi menarik bagi Model Bahasa Besar ialah analisis sentimen. Dalam hal ini, model dilatih untuk mengenali dan mengkategorikan keadaan emosi dan sentimen yang terdapat dalam teks beranotasi. Perisian ini boleh mengenal pasti emosi seperti positif, negatif, berkecuali, dan sentimen rumit lain. Ini boleh memberikan pandangan yang berharga tentang maklum balas dan pandangan pelanggan tentang pelbagai produk dan perkhidmatan.
- Memahami, Merumus dan Mengelaskan Teks: LLM mewujudkan struktur yang berdaya maju untuk perisian AI untuk mentafsir teks dan konteksnya. Dengan mengarahkan model untuk memahami dan meneliti sejumlah besar data, LLM membolehkan model AI untuk memahami, meringkaskan dan juga mengkategorikan teks dalam pelbagai bentuk dan corak.
- Menjawab Soalan: Model Bahasa Besar melengkapkan sistem Penjawab Soalan (QA) dengan keupayaan untuk memahami dan bertindak balas dengan tepat kepada pertanyaan bahasa semula jadi pengguna. Contoh popular kes penggunaan ini termasuk ChatGPT dan BERT, yang mengkaji konteks pertanyaan dan menapis koleksi teks yang luas untuk menyampaikan respons yang berkaitan kepada soalan pengguna.

Tagging Part-of-Speech (POS).
Perkataan dalam ayat ditandakan dengan fungsi tatabahasanya, seperti kata kerja, kata nama, kata adjektif, dsb. Proses ini membantu model dalam memahami tatabahasa dan kaitan antara perkataan.

Pengiktirafan Entiti Dinamakan (NER)
Entiti bernama seperti organisasi, lokasi dan orang dalam ayat ditanda. Latihan ini membantu model dalam mentafsir makna semantik perkataan dan frasa dan memberikan respons yang lebih tepat.

Analisis Sentimen
Data teks diberikan label sentimen seperti positif, neutral atau negatif, membantu model memahami nada emosi ayat. Ia amat berguna dalam menjawab pertanyaan yang melibatkan emosi dan pendapat.
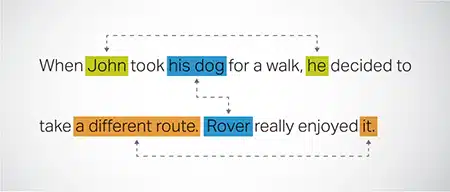
Resolusi Coreference
Mengenal pasti dan menyelesaikan kejadian di mana entiti yang sama dirujuk dalam bahagian teks yang berbeza. Langkah ini membantu model memahami konteks ayat, dengan itu membawa kepada tindak balas yang koheren.
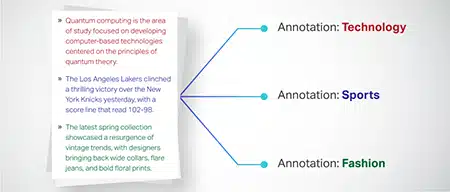
Pengelasan Teks
Data teks dikategorikan ke dalam kumpulan yang dipratentukan seperti ulasan produk atau artikel berita. Ini membantu model dalam membezakan genre atau topik teks, menghasilkan respons yang lebih berkaitan.
Tawaran Shaip
Saip menawarkan pelbagai perkhidmatan untuk membantu organisasi mengurus, menganalisis dan memanfaatkan sepenuhnya data mereka.
Data Web-Scraping
Satu perkhidmatan utama yang ditawarkan oleh Shaip ialah pengikisan data. Ini melibatkan pengekstrakan data daripada URL khusus domain. Dengan menggunakan alat dan teknik automatik, Shaip boleh dengan cepat dan cekap mengikis jumlah data yang besar daripada pelbagai tapak web, Manual Produk, Dokumentasi Teknikal, Forum dalam talian, Ulasan Dalam Talian, Data Perkhidmatan Pelanggan, Dokumen Kawal Selia Industri dan lain-lain. Proses ini boleh menjadi tidak ternilai untuk perniagaan apabila mengumpul data yang relevan dan khusus daripada pelbagai sumber.

Terjemahan Mesin
Bangunkan model menggunakan set data berbilang bahasa yang luas dipasangkan dengan transkripsi yang sepadan untuk menterjemah teks merentas pelbagai bahasa. Proses ini membantu merungkai halangan linguistik dan menggalakkan kebolehcapaian maklumat.
Pengekstrakan & Penciptaan Taksonomi
Shaip boleh membantu dengan pengekstrakan dan penciptaan taksonomi. Ini melibatkan pengelasan dan pengkategorian data ke dalam format berstruktur yang mencerminkan hubungan antara titik data yang berbeza. Ini amat berguna untuk perniagaan dalam mengatur data mereka, menjadikannya lebih mudah diakses dan lebih mudah untuk dianalisis. Sebagai contoh, dalam perniagaan e-dagang, data produk mungkin dikategorikan berdasarkan jenis produk, jenama, harga, dsb., menjadikannya lebih mudah untuk pelanggan menavigasi katalog produk.
Pengumpulan Data
Perkhidmatan pengumpulan data kami menyediakan data dunia sebenar atau sintetik kritikal yang diperlukan untuk melatih algoritma AI generatif dan meningkatkan ketepatan dan keberkesanan model anda. Data tidak berat sebelah, beretika dan bersumberkan secara bertanggungjawab sambil mengambil kira privasi dan keselamatan data.

Soal Jawab
Menjawab soalan (QA) ialah subbidang pemprosesan bahasa semula jadi yang tertumpu pada menjawab soalan secara automatik dalam bahasa manusia. Sistem QA dilatih mengenai teks dan kod yang meluas, membolehkan mereka mengendalikan pelbagai jenis soalan, termasuk soalan fakta, definisi dan berasaskan pendapat. Pengetahuan domain adalah penting untuk membangunkan model QA yang disesuaikan dengan bidang tertentu seperti sokongan pelanggan, penjagaan kesihatan atau rantaian bekalan. Walau bagaimanapun, pendekatan QA generatif membenarkan model menjana teks tanpa pengetahuan domain, bergantung semata-mata pada konteks.
Pasukan pakar kami boleh mengkaji dengan teliti dokumen atau manual yang komprehensif untuk menjana pasangan Soalan-Jawapan, memudahkan penciptaan Generatif AI untuk perniagaan. Pendekatan ini boleh menangani pertanyaan pengguna dengan berkesan dengan melombong maklumat berkaitan daripada korpus yang luas. Pakar kami yang diperakui memastikan penghasilan pasangan Soal Jawab berkualiti tinggi yang merangkumi pelbagai topik dan domain.

Ringkasan Teks
Pakar kami mampu menyaring perbualan yang komprehensif atau dialog yang panjang, menyampaikan ringkasan yang ringkas dan bernas daripada data teks yang luas.

Penjanaan Teks
Latih model menggunakan set data luas teks dalam pelbagai gaya, seperti artikel berita, fiksyen dan puisi. Model ini kemudiannya boleh menjana pelbagai jenis kandungan, termasuk berita, entri blog atau siaran media sosial, menawarkan penyelesaian yang menjimatkan kos dan menjimatkan masa untuk penciptaan kandungan.
Pengenalan suara
Membangunkan model yang mampu memahami bahasa pertuturan untuk pelbagai aplikasi. Ini termasuk pembantu yang diaktifkan suara, perisian imlak dan alat terjemahan masa nyata. Proses ini melibatkan penggunaan set data komprehensif yang terdiri daripada rakaman audio bahasa pertuturan, dipasangkan dengan transkrip yang sepadan.

Cadangan Produk
Bangunkan model menggunakan set data yang luas bagi sejarah pembelian pelanggan, termasuk label yang menunjukkan produk yang pelanggan cenderung untuk membeli. Matlamatnya adalah untuk memberikan cadangan yang tepat kepada pelanggan, dengan itu meningkatkan jualan dan meningkatkan kepuasan pelanggan.
Kapsyen Imej
Revolusikan proses tafsiran imej anda dengan perkhidmatan Kapsyen Imej dipacu AI kami yang terkini. Kami menyelitkan daya hidup ke dalam gambar dengan menghasilkan penerangan yang tepat dan bermakna mengikut konteks. Ini membuka jalan untuk kemungkinan penglibatan dan interaksi yang inovatif dengan kandungan visual anda untuk khalayak anda.

Latihan Perkhidmatan Teks-ke-Pertuturan
Kami menyediakan set data yang luas yang terdiri daripada rakaman audio pertuturan manusia, sesuai untuk melatih model AI. Model ini mampu menjana suara semula jadi dan menarik untuk aplikasi anda, sekali gus memberikan pengalaman bunyi yang tersendiri dan mengasyikkan untuk pengguna anda.



