




Memperkasakan Penjagaan Kesihatan dengan Generatif AI: Merevolusikan Diagnosis dan Rawatan
Dalam beberapa tahun kebelakangan ini, kecerdasan buatan (AI) telah mencapai kemajuan yang ketara dalam pelbagai industri, dan penjagaan kesihatan tidak terkecuali. AI Generatif, subset AI tertumpu
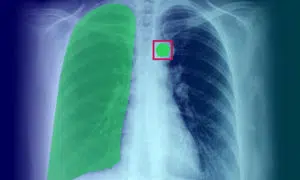
Anotasi Imej Perubatan: Definisi, Aplikasi, Kes & Jenis Penggunaan
Anotasi imej perubatan memainkan peranan penting dalam menyediakan algoritma pembelajaran mesin dan model AI dengan data latihan yang diperlukan. Proses ini penting untuk

Etika dan Bias: Menavigasi Cabaran Kerjasama Manusia-AI dalam Penilaian Model
Dalam usaha untuk memanfaatkan kuasa transformatif kecerdasan buatan (AI), komuniti teknologi menghadapi cabaran kritikal: memastikan integriti etika dan meminimumkan berat sebelah

Sentuhan Manusia: Meningkatkan Kreativiti AI dengan Penilaian Subjektif
Dalam dunia kecerdasan buatan (AI) yang berkembang pesat, pencarian kreativiti bukan lagi sekadar usaha manusia. Teknologi AI hari ini semakin rosak

Memaksimumkan Perkaitan Carian dengan Pelabelan Data: Petua dan Amalan Terbaik
Pengguna hari ini tenggelam dalam sejumlah besar maklumat, yang menjadikan pencarian maklumat yang mereka perlukan menjadi rumit. Perkaitan carian mengukur ketepatan maklumat an

Merapatkan Jurang: Mengintegrasikan Intuisi Manusia ke dalam Penilaian Model AI
Pengenalan Dalam era di mana kecerdasan buatan (AI) membentuk setiap aspek kehidupan kita, integrasi intuisi manusia ke dalam penilaian model AI muncul sebagai

Set Data Penjagaan Kesihatan Sumber Terbuka Terbaik untuk Projek Pembelajaran Mesin
Sistem penjagaan kesihatan global menghasilkan sejumlah besar data perubatan setiap hari, yang berpotensi untuk digunakan untuk aplikasi pembelajaran mesin.

Menavigasi Privasi Data dalam AI: Strategi untuk Pematuhan dan Inovasi
Pengenalan Dalam landskap kecerdasan buatan (AI) yang berkembang pesat, syarikat seperti OpenAI menghadapi cabaran besar dalam mengimbangi keperluan data yang tidak dapat dipuaskan dengan ketat.
Masa Depan Data dengan Pengecaman Watak Pintar (ICR)
Nota tulisan tangan memegang daya tarikan istimewa walaupun dalam dunia digital kita. Pengecaman Aksara Pintar (ICR) membantu merapatkan jurang analog dan digital, menukar teks tulisan tangan

Kesan NLP terhadap Diagnostik Penjagaan Kesihatan
Pemprosesan Bahasa Asli (NLP) mengubah cara kita berinteraksi dengan teknologi. Ia memproses bahasa manusia untuk membuka kunci potensi maklumat yang luas. Teknologi ini mempunyai potensi yang sama

Memilih Set Data Pengecaman Pertuturan yang Tepat untuk Model AI Anda
Bayangkan berinteraksi dengan Siri atau Alexa. Keupayaan mereka untuk memahami ucapan kita sangat menarik. Keupayaan ini berpunca daripada set data yang digunakan dalam latihan mereka. Ini

Set Data Penjagaan Kesihatan: Boon for Healthcare AI
Kecerdasan buatan, istilah yang pernah ditemui kebanyakannya dalam fiksyen sains, kini menjadi realiti yang memacu pertumbuhan pelbagai industri. Perundingan Strategi Bergerak Seterusnya

Pembelajaran Pengukuhan dengan Maklum Balas Manusia: Definisi dan Langkah
Pembelajaran pengukuhan (RL) ialah sejenis pembelajaran mesin. Dalam pendekatan ini, algoritma belajar membuat keputusan melalui percubaan dan kesilapan, sama seperti yang dilakukan manusia.

Punca Halusinasi AI (dan Teknik Mengurangkannya)
Halusinasi AI merujuk kepada keadaan di mana model AI, terutamanya model bahasa besar (LLM), menjana maklumat yang kelihatan benar tetapi tidak betul atau tidak berkaitan dengan

Apakah Pengesahan Klinikal? Panduan Anda untuk Amalan dan Proses Terbaik
Fikirkan senario di mana alat diagnostik baharu dibangunkan. Doktor teruja dengan potensinya. Namun, sebelum mengintegrasikannya ke dalam penjagaan rutin, mereka

Kepentingan AI Beretika / AI Adil dan Jenis Bias yang Perlu Dielakkan
Dalam bidang kecerdasan buatan (AI) yang berkembang pesat, tumpuan pada pertimbangan etika dan keadilan adalah lebih daripada keperluan moral—ia adalah keperluan asas untuk

Ringkasan Rekod Perubatan AI: Definisi, Cabaran dan Amalan Terbaik
Pertumbuhan rekod perubatan dalam industri penjagaan kesihatan telah menjadi satu cabaran dan peluang. Bayangkan dunia di mana setiap butiran dalam a

Abstraksi Data Klinikal: Definisi, Proses dan banyak lagi
Hospital dan klinik menghadapi ribuan pesakit setiap tahun. Ini memerlukan sejumlah besar doktor dan jururawat yang berdedikasi. Mereka bekerja tanpa jemu untuk memberikan penjagaan

Data sintetik dalam penjagaan kesihatan: Definisi, Faedah dan Cabaran
Bayangkan senario di mana penyelidik sedang membangunkan ubat baharu. Mereka memerlukan data pesakit yang luas untuk ujian, tetapi terdapat kebimbangan yang ketara tentang privasi dan

Penentuan Pakar HIPAA untuk Nyah Pengenalan
Akta Mudah Alih dan Akauntabiliti Insurans Kesihatan (HIPAA) menetapkan piawaian untuk melindungi data pesakit dalam penjagaan kesihatan. Aspek penting dalam hal ini ialah nyah mengenal pasti Dilindungi

Merintis Penyelidikan Onkologi dengan NLP: The Shaip Breakthrough
Muat Turun Kajian Kes Dalam usaha untuk menakluk kanser, data adalah sama pentingnya dengan keazaman. Di Shaip, kami berbangga kerana telah mendayakan lonjakan besar
Kuasa Pemprosesan Bahasa Semulajadi (NLP) dalam Radiologi: Meningkatkan Diagnosis dan Kecekapan
Radiologi memainkan peranan penting dalam penjagaan kesihatan. Ia menggunakan teknik pengimejan seperti imbasan CT, X-ray, dan MRI untuk mendiagnosis dan merawat pelbagai keadaan. Bahasa Semulajadi

Peranan Pemprosesan Bahasa Semulajadi (NLP) Dalam Onkologi
Kanser menimbulkan cabaran kesihatan yang ketara di seluruh dunia. Ia berlaku apabila sel tumbuh dan merebak dengan cara yang tidak terkawal. Ia merupakan punca utama kedua kematian

Semua yang Anda Perlu Tahu Tentang Pembelajaran Peneguhan daripada Maklum Balas Manusia
2023 menyaksikan peningkatan besar dalam penggunaan alatan AI seperti ChatGPT. Lonjakan ini memulakan perdebatan yang meriah dan orang ramai membincangkan faedah AI,

Kuasa AI dalam Industri Automotif
Apabila ia datang untuk menyepadukan AI ke dalam kereta, dunia berada di persimpangan yang luar biasa. Bayangkan memandu di jalan yang sibuk dengan AI, menguruskan anda

Faedah Teks kepada Ucapan Merentasi Industri
Teknologi Text-to-speech (TTS) ialah penyelesaian inovatif yang menukar teks bertulis kepada perkataan yang dituturkan. Ia telah menjadi pengubah permainan dalam beberapa industri dan telah merevolusikan

Anotasi Data A hingga Z
Panduan Pemula untuk Anotasi Data: Petua dan Amalan Terbaik Panduan Pembeli Terunggul 2024 Jadual Pengenalan Indeks Apakah Pembelajaran Mesin? Apa itu

Panduan Nyahpengenalpastian Data: Segala-galanya yang Perlu Dikenali oleh Pemula (pada tahun 2024)
Dalam era transformasi digital, organisasi penjagaan kesihatan dengan pantas mengalihkan operasi mereka kepada platform digital. Walaupun ini membawa kecekapan dan proses yang diperkemas, ia juga

AI Generatif dalam Penjagaan Kesihatan: Aplikasi, Kelebihan, Cabaran dan Trend Masa Depan
Penjagaan kesihatan sentiasa menjadi bidang di mana inovasi dihargai dan penting untuk menyelamatkan nyawa. Walaupun kemajuan teknologi, industri penjagaan kesihatan masih menghadapi cabaran yang berlarutan.

Perbezaan Antara AI Bertanggungjawab & AI Beretika
Pasaran AI global yang berkembang pesat dijangka mencecah $1847 bilion pada 2030. Dengan AI menjadi tumpuan utama dalam kehidupan kita, mengetahui jenis



















Memperkasakan Penjagaan Kesihatan dengan Generatif AI: Merevolusikan Diagnosis dan Rawatan
Dalam beberapa tahun kebelakangan ini, kecerdasan buatan (AI) telah mencapai kemajuan yang ketara dalam pelbagai industri, dan penjagaan kesihatan tidak terkecuali. AI Generatif, subset AI tertumpu
Anotasi Imej Perubatan: Definisi, Aplikasi, Kes & Jenis Penggunaan
Anotasi imej perubatan memainkan peranan penting dalam menyediakan algoritma pembelajaran mesin dan model AI dengan data latihan yang diperlukan. Proses ini penting untuk
Etika dan Bias: Menavigasi Cabaran Kerjasama Manusia-AI dalam Penilaian Model
Dalam usaha untuk memanfaatkan kuasa transformatif kecerdasan buatan (AI), komuniti teknologi menghadapi cabaran kritikal: memastikan integriti etika dan meminimumkan berat sebelah
Sentuhan Manusia: Meningkatkan Kreativiti AI dengan Penilaian Subjektif
Dalam dunia kecerdasan buatan (AI) yang berkembang pesat, pencarian kreativiti bukan lagi sekadar usaha manusia. Teknologi AI hari ini semakin rosak
Memaksimumkan Perkaitan Carian dengan Pelabelan Data: Petua dan Amalan Terbaik
Pengguna hari ini tenggelam dalam sejumlah besar maklumat, yang menjadikan pencarian maklumat yang mereka perlukan menjadi rumit. Perkaitan carian mengukur ketepatan maklumat an
Merapatkan Jurang: Mengintegrasikan Intuisi Manusia ke dalam Penilaian Model AI
Pengenalan Dalam era di mana kecerdasan buatan (AI) membentuk setiap aspek kehidupan kita, integrasi intuisi manusia ke dalam penilaian model AI muncul sebagai
Set Data Penjagaan Kesihatan Sumber Terbuka Terbaik untuk Projek Pembelajaran Mesin
Sistem penjagaan kesihatan global menghasilkan sejumlah besar data perubatan setiap hari, yang berpotensi untuk digunakan untuk aplikasi pembelajaran mesin.
Menavigasi Privasi Data dalam AI: Strategi untuk Pematuhan dan Inovasi
Pengenalan Dalam landskap kecerdasan buatan (AI) yang berkembang pesat, syarikat seperti OpenAI menghadapi cabaran besar dalam mengimbangi keperluan data yang tidak dapat dipuaskan dengan ketat.
Masa Depan Data dengan Pengecaman Watak Pintar (ICR)
Nota tulisan tangan memegang daya tarikan istimewa walaupun dalam dunia digital kita. Pengecaman Aksara Pintar (ICR) membantu merapatkan jurang analog dan digital, menukar teks tulisan tangan
Kesan NLP terhadap Diagnostik Penjagaan Kesihatan
Pemprosesan Bahasa Asli (NLP) mengubah cara kita berinteraksi dengan teknologi. Ia memproses bahasa manusia untuk membuka kunci potensi maklumat yang luas. Teknologi ini mempunyai potensi yang sama
Memilih Set Data Pengecaman Pertuturan yang Tepat untuk Model AI Anda
Bayangkan berinteraksi dengan Siri atau Alexa. Keupayaan mereka untuk memahami ucapan kita sangat menarik. Keupayaan ini berpunca daripada set data yang digunakan dalam latihan mereka. Ini
Set Data Penjagaan Kesihatan: Boon for Healthcare AI
Kecerdasan buatan, istilah yang pernah ditemui kebanyakannya dalam fiksyen sains, kini menjadi realiti yang memacu pertumbuhan pelbagai industri. Perundingan Strategi Bergerak Seterusnya
Pembelajaran Pengukuhan dengan Maklum Balas Manusia: Definisi dan Langkah
Pembelajaran pengukuhan (RL) ialah sejenis pembelajaran mesin. Dalam pendekatan ini, algoritma belajar membuat keputusan melalui percubaan dan kesilapan, sama seperti yang dilakukan manusia.
Punca Halusinasi AI (dan Teknik Mengurangkannya)
Halusinasi AI merujuk kepada keadaan di mana model AI, terutamanya model bahasa besar (LLM), menjana maklumat yang kelihatan benar tetapi tidak betul atau tidak berkaitan dengan
Apakah Pengesahan Klinikal? Panduan Anda untuk Amalan dan Proses Terbaik
Fikirkan senario di mana alat diagnostik baharu dibangunkan. Doktor teruja dengan potensinya. Namun, sebelum mengintegrasikannya ke dalam penjagaan rutin, mereka
Kepentingan AI Beretika / AI Adil dan Jenis Bias yang Perlu Dielakkan
Dalam bidang kecerdasan buatan (AI) yang berkembang pesat, tumpuan pada pertimbangan etika dan keadilan adalah lebih daripada keperluan moral—ia adalah keperluan asas untuk
Ringkasan Rekod Perubatan AI: Definisi, Cabaran dan Amalan Terbaik
Pertumbuhan rekod perubatan dalam industri penjagaan kesihatan telah menjadi satu cabaran dan peluang. Bayangkan dunia di mana setiap butiran dalam a
Abstraksi Data Klinikal: Definisi, Proses dan banyak lagi
Hospital dan klinik menghadapi ribuan pesakit setiap tahun. Ini memerlukan sejumlah besar doktor dan jururawat yang berdedikasi. Mereka bekerja tanpa jemu untuk memberikan penjagaan
Data sintetik dalam penjagaan kesihatan: Definisi, Faedah dan Cabaran
Bayangkan senario di mana penyelidik sedang membangunkan ubat baharu. Mereka memerlukan data pesakit yang luas untuk ujian, tetapi terdapat kebimbangan yang ketara tentang privasi dan
Penentuan Pakar HIPAA untuk Nyah Pengenalan
Akta Mudah Alih dan Akauntabiliti Insurans Kesihatan (HIPAA) menetapkan piawaian untuk melindungi data pesakit dalam penjagaan kesihatan. Aspek penting dalam hal ini ialah nyah mengenal pasti Dilindungi
Merintis Penyelidikan Onkologi dengan NLP: The Shaip Breakthrough
Muat Turun Kajian Kes Dalam usaha untuk menakluk kanser, data adalah sama pentingnya dengan keazaman. Di Shaip, kami berbangga kerana telah mendayakan lonjakan besar
Kuasa Pemprosesan Bahasa Semulajadi (NLP) dalam Radiologi: Meningkatkan Diagnosis dan Kecekapan
Radiologi memainkan peranan penting dalam penjagaan kesihatan. Ia menggunakan teknik pengimejan seperti imbasan CT, X-ray, dan MRI untuk mendiagnosis dan merawat pelbagai keadaan. Bahasa Semulajadi
Peranan Pemprosesan Bahasa Semulajadi (NLP) Dalam Onkologi
Kanser menimbulkan cabaran kesihatan yang ketara di seluruh dunia. Ia berlaku apabila sel tumbuh dan merebak dengan cara yang tidak terkawal. Ia merupakan punca utama kedua kematian
Semua yang Anda Perlu Tahu Tentang Pembelajaran Peneguhan daripada Maklum Balas Manusia
2023 menyaksikan peningkatan besar dalam penggunaan alatan AI seperti ChatGPT. Lonjakan ini memulakan perdebatan yang meriah dan orang ramai membincangkan faedah AI,
Kuasa AI dalam Industri Automotif
Apabila ia datang untuk menyepadukan AI ke dalam kereta, dunia berada di persimpangan yang luar biasa. Bayangkan memandu di jalan yang sibuk dengan AI, menguruskan anda
Faedah Teks kepada Ucapan Merentasi Industri
Teknologi Text-to-speech (TTS) ialah penyelesaian inovatif yang menukar teks bertulis kepada perkataan yang dituturkan. Ia telah menjadi pengubah permainan dalam beberapa industri dan telah merevolusikan
Anotasi Data A hingga Z
Panduan Pemula untuk Anotasi Data: Petua dan Amalan Terbaik Panduan Pembeli Terunggul 2024 Jadual Pengenalan Indeks Apakah Pembelajaran Mesin? Apa itu
Panduan Nyahpengenalpastian Data: Segala-galanya yang Perlu Dikenali oleh Pemula (pada tahun 2024)
Dalam era transformasi digital, organisasi penjagaan kesihatan dengan pantas mengalihkan operasi mereka kepada platform digital. Walaupun ini membawa kecekapan dan proses yang diperkemas, ia juga
AI Generatif dalam Penjagaan Kesihatan: Aplikasi, Kelebihan, Cabaran dan Trend Masa Depan
Penjagaan kesihatan sentiasa menjadi bidang di mana inovasi dihargai dan penting untuk menyelamatkan nyawa. Walaupun kemajuan teknologi, industri penjagaan kesihatan masih menghadapi cabaran yang berlarutan.
Perbezaan Antara AI Bertanggungjawab & AI Beretika
Pasaran AI global yang berkembang pesat dijangka mencecah $1847 bilion pada 2030. Dengan AI menjadi tumpuan utama dalam kehidupan kita, mengetahui jenis

Apakah NLP? Bagaimana ia Berfungsi, Faedah, Cabaran, Contoh
Muat turun Infografik Apakah itu NLP? Pemprosesan Bahasa Asli (NLP) ialah subbidang kecerdasan buatan (AI). Ia membolehkan robot menganalisis dan memahami bahasa manusia,

OCR – Definisi, Faedah, Cabaran dan Kes Penggunaan [Infografik]
OCR ialah teknologi yang membolehkan mesin membaca teks & imej bercetak. Ia sering digunakan dalam aplikasi perniagaan, seperti mendigitalkan dokumen untuk penyimpanan atau pemprosesan, & dalam aplikasi pengguna, seperti mengimbas resit untuk pembayaran balik perbelanjaan.

Keadaan Perbualan AI 2022
State ofConversational AI 2022 Apa itu AI Conversational? Kaedah teratur dan cerdas untuk menawarkan pengalaman perbualan percakapan tomimik dengan orang sebenar, melalui digital dan telekomunikasi

Apakah Pengumpulan Data? Segala-galanya Yang Pemula Perlu Tahu
Model #AI/ #ML pintar ada di mana-mana, sama ada, Model penjagaan kesihatan ramalan, diagnosis proaktif,

Apa itu Pelabelan Data? Semua yang Perlu Diketahui oleh Pemula
Muat turun model AI Infografik Pintar perlu dilatih secara meluas untuk dapat mengenal pasti corak, objek, dan akhirnya dapat membuat keputusan yang boleh dipercayai. Namun, terlatih