
Kunci untuk Mengatasi Halangan Pembangunan AI: Data Lebih Boleh dipercayai
Hari ini, rata-rata orang kini mempunyai jutaan kali lebih banyak kuasa pengkomputeran dari poket mereka daripada NASA yang terpaksa melakukan pendaratan bulan pada tahun 1969. Peranti yang ada di mana-mana yang dengan mudah menunjukkan banyak kekuatan pengkomputeran juga memenuhi syarat lain untuk zaman keemasan AI: banyak data. Menurut pandangan dari Information Overload Research Group, 90% data dunia dibuat dalam dua tahun terakhir. Sekarang bahawa pertumbuhan eksponensial dalam daya pengkomputeran akhirnya berkumpul dengan pertumbuhan meteorik yang sama dalam penjanaan data, inovasi data AI meletup begitu banyak sehingga beberapa pakar berpendapat akan memulai Revolusi Industri Keempat.
Data dari National Venture Capital Association menunjukkan bahawa sektor AI mencatatkan pelaburan $ 6.9 bilion pada suku pertama tahun 2020. Tidak sukar untuk melihat potensi alat AI kerana sudah disadap di sekitar kita. Beberapa kes penggunaan yang lebih jelas untuk produk AI adalah enjin cadangan di sebalik aplikasi kegemaran kami seperti Spotify dan Netflix. Walaupun senang menemui artis baru untuk didengarkan atau rancangan TV baru untuk menonton, pelaksanaan ini agak rendah. Skor ujian gred algoritma lain - sebahagiannya menentukan di mana pelajar diterima masuk ke kuliah - dan masih ada yang meneliti resume calon, menentukan pemohon mana yang mendapat pekerjaan tertentu. Beberapa alat AI bahkan boleh membawa implikasi hidup atau mati, seperti model AI yang meneliti barah payudara (yang mengatasi doktor).
Walaupun terdapat pertumbuhan yang stabil dalam kedua-dua contoh pembangunan AI di dunia nyata dan bilangan syarikat yang baru berusaha untuk mencipta generasi alat transformasi seterusnya, cabaran untuk pembangunan dan pelaksanaan yang berkesan tetap ada. Khususnya, output AI hanya seakurat input, yang bermaksud kualiti adalah yang terpenting.

Menavigasi Permintaan Pematuhan Kompleks
Seolah-olah mencari data berkualiti tidak cukup sukar, beberapa industri yang dapat memperoleh hasil maksimal dari inovasi data AI juga paling banyak diatur. Penjagaan kesihatan mungkin merupakan contoh terbaik, dan sementara tinjauan dari HIT Infrastruktur mendapati bahawa 91% orang dalam industri berpendapat bahawa teknologi dapat meningkatkan akses ke perawatan, optimisme itu ditolak oleh kenyataan bahawa 75% melihatnya sebagai ancaman terhadap keselamatan dan privasi pesakit - dan pesakit bukan satu-satunya yang berisiko.
Peraturan menyeluruh yang disahkan melalui Undang-Undang Kebolehtanggungjawaban dan Kebertanggungjawaban Insurans Kesihatan kini berpotongan dengan berbagai rintangan pematuhan data tempatan seperti Peraturan Perlindungan Data Umum Eropah, Undang-undang Privasi Pengguna California di Amerika Syarikat, dan Undang-Undang Perlindungan Data Peribadi di Singapura. Peraturan-peraturan tempatan ini akan digabungkan lebih banyak lagi, dan ketika telehealth muncul sebagai sumber data penjagaan kesihatan yang lebih penting, kemungkinan peraturan akan mendapat pegangan yang lebih ketat terhadap data pesakit dalam perjalanan. Hasilnya, platform cloud Shaip yang selamat dan patuh akan terbukti menjadi cara yang lebih berharga untuk mengumpulkan dan mengakses data kesihatan untuk melatih produk AI.
Maklumat yang dapat dikenal pasti secara peribadi boleh menjadi ancaman besar terhadap perkembangan AI anda, tetapi bahkan pelaksanaan yang sepenuhnya sesuai berisiko jika tidak dapat memberikan jenis hasil yang tepat yang hanya dilengkapi dengan data latihan yang beragam. Satu kajian tahun 2020 dalam Journal of the American Medical Association menunjukkan bahawa algoritma pembelajaran mesin dalam bidang perubatan paling sering dilatih dengan data dari pesakit di California, New York, dan Massachusetts. Memandangkan pesakit-pesakit ini mewakili kurang dari seperlima populasi AS, untuk mengatakan tidak ada yang lain di dunia, sukar untuk membayangkan bagaimana model-model ini dapat menghasilkan apa-apa kecuali hasil yang berat sebelah.

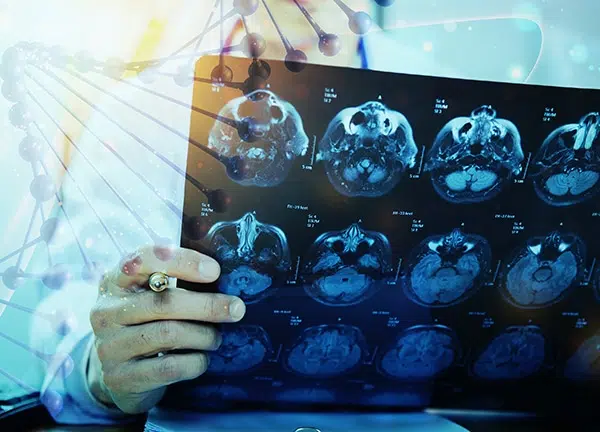 Menyedari kesukaran mendapatkan maklumat yang berpatutan, beragam dari segi geografi, Shaip menawarkan data penjagaan kesihatan berlesen dari pelbagai wilayah yang dikuruskan secara khusus dengan tujuan membina algoritma yang tepat. Data ini datang dalam bentuk teks, seperti rekod perubatan atau maklumat tuntutan, pengimejan diagnostik perubatan seperti imbasan CT, audio seperti nota lisan dari doktor atau perbualan antara doktor dan pesakit, dan bahkan video dari hasil MRI. Ia juga dikenali sepenuhnya dan tidak disebutkan namanya, melindungi organisasi anda dari implikasi etika dan kewangan yang boleh berlaku setelah berlakunya pelanggaran terhadap peningkatan jumlah peraturan yang mengatur data dari dalam dan luar negara.
Menyedari kesukaran mendapatkan maklumat yang berpatutan, beragam dari segi geografi, Shaip menawarkan data penjagaan kesihatan berlesen dari pelbagai wilayah yang dikuruskan secara khusus dengan tujuan membina algoritma yang tepat. Data ini datang dalam bentuk teks, seperti rekod perubatan atau maklumat tuntutan, pengimejan diagnostik perubatan seperti imbasan CT, audio seperti nota lisan dari doktor atau perbualan antara doktor dan pesakit, dan bahkan video dari hasil MRI. Ia juga dikenali sepenuhnya dan tidak disebutkan namanya, melindungi organisasi anda dari implikasi etika dan kewangan yang boleh berlaku setelah berlakunya pelanggaran terhadap peningkatan jumlah peraturan yang mengatur data dari dalam dan luar negara.
Mengatasi Halangan Pembangunan AI
Usaha pengembangan AI merangkumi rintangan yang besar tidak kira industri apa yang mereka lakukan, dan proses mendapatkan dari idea yang layak ke produk yang berjaya penuh dengan kesulitan. Di antara cabaran memperoleh data yang tepat dan keperluan untuk menganonimkannya untuk mematuhi semua peraturan yang relevan, terasa seperti benar-benar membina dan melatih algoritma adalah bahagian yang mudah.
Untuk memberi organisasi anda setiap kelebihan yang diperlukan dalam usaha merancang pengembangan AI baru yang inovatif, anda harus mempertimbangkan untuk bekerjasama dengan syarikat seperti Shaip. Chetan Parikh dan Vatsal Ghiya mengasaskan Shaip untuk membantu syarikat merancang jenis penyelesaian yang dapat mengubah penjagaan kesihatan di AS Setelah lebih dari 16 tahun berniaga, syarikat kami telah berkembang sehingga merangkumi lebih dari 600 ahli pasukan, dan kami telah bekerjasama dengan ratusan pelanggan menjadikan idea menarik menjadi penyelesaian AI.
Dengan orang, proses, dan platform kami yang berfungsi untuk organisasi anda, anda dapat segera membuka empat faedah berikut dan melancarkan projek anda ke arah kejayaan yang berjaya:
1. Keupayaan untuk membebaskan saintis data anda
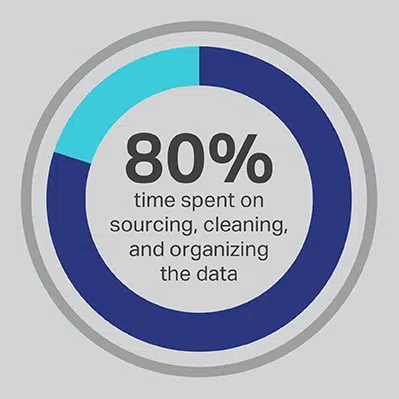
Tidak dapat dijangkakan bahawa proses pengembangan AI memerlukan banyak masa, tetapi anda selalu dapat mengoptimumkan fungsi yang paling banyak menghabiskan masa oleh pasukan anda. Anda mengupah saintis data anda kerana mereka pakar dalam pengembangan algoritma canggih dan model pembelajaran mesin, tetapi penyelidikan secara konsisten menunjukkan bahawa pekerja ini sebenarnya menghabiskan 80% masa mereka untuk mendapatkan, membersihkan, dan mengatur data yang akan menggerakkan projek. Lebih daripada tiga perempat (76%) saintis data melaporkan bahawa proses pengumpulan data biasa ini juga merupakan bahagian pekerjaan mereka yang paling tidak disukai, tetapi keperluan untuk data yang berkualiti meninggalkan hanya 20% masa mereka untuk pembangunan yang sebenarnya, iaitu karya yang paling menarik dan merangsang intelektual bagi banyak saintis data. Dengan mendapatkan data melalui vendor pihak ketiga seperti Shaip, sebuah syarikat boleh membiarkan jurutera data yang mahal dan berbakat menggunakan sumber pekerjaan mereka sebagai penyedia data dan sebaliknya menghabiskan masa mereka pada bahagian penyelesaian AI di mana mereka dapat menghasilkan nilai terbanyak.
2. Keupayaan untuk mencapai hasil yang lebih baik
 Banyak pemimpin pembangunan AI memutuskan untuk menggunakan data sumber terbuka atau sumber banyak untuk mengurangkan perbelanjaan, tetapi keputusan ini hampir selalu memakan kos lebih lama dalam jangka panjang. Jenis data ini tersedia, tetapi tidak dapat menandingi kualiti set data yang disusun dengan teliti. Data sumber ramai khususnya terdapat kesilapan, peninggalan, dan ketidaktepatan, dan walaupun masalah ini kadang-kadang dapat diselesaikan semasa proses pembangunan di bawah pengawasan jurutera anda, ia memerlukan iterasi tambahan yang tidak diperlukan jika anda memulakan dengan yang lebih tinggi - data kualiti dari awal.
Banyak pemimpin pembangunan AI memutuskan untuk menggunakan data sumber terbuka atau sumber banyak untuk mengurangkan perbelanjaan, tetapi keputusan ini hampir selalu memakan kos lebih lama dalam jangka panjang. Jenis data ini tersedia, tetapi tidak dapat menandingi kualiti set data yang disusun dengan teliti. Data sumber ramai khususnya terdapat kesilapan, peninggalan, dan ketidaktepatan, dan walaupun masalah ini kadang-kadang dapat diselesaikan semasa proses pembangunan di bawah pengawasan jurutera anda, ia memerlukan iterasi tambahan yang tidak diperlukan jika anda memulakan dengan yang lebih tinggi - data kualiti dari awal.
Mengandalkan data sumber terbuka adalah jalan pintas umum lain yang dilengkapi dengan perangkap sendiri. Kekurangan pembezaan adalah salah satu masalah terbesar, kerana algoritma yang dilatih menggunakan data sumber terbuka lebih mudah ditiru daripada yang dibina berdasarkan set data berlesen. Dengan melalui laluan ini, anda mengundang persaingan dari peserta lain di ruang yang dapat menurunkan harga anda dan mengambil bahagian pasaran pada bila-bila masa. Apabila anda bergantung pada Shaip, anda mengakses data berkualiti tinggi yang dikumpulkan oleh tenaga kerja terurus yang terampil, dan kami dapat memberikan anda lesen eksklusif untuk set data khusus yang menghalang pesaing mencipta semula harta intelektual anda yang dimenangkan.
3. Akses kepada profesional yang berpengalaman
 Walaupun senarai dalaman anda merangkumi jurutera mahir dan saintis data berbakat, alat AI anda dapat memanfaatkan kebijaksanaan yang hanya ada melalui pengalaman. Pakar subjek kami telah menerajui banyak implementasi AI di bidangnya dan mempelajari pelajaran berharga sepanjang perjalanan, dan tujuan utamanya adalah untuk membantu anda mencapai tujuan anda.
Walaupun senarai dalaman anda merangkumi jurutera mahir dan saintis data berbakat, alat AI anda dapat memanfaatkan kebijaksanaan yang hanya ada melalui pengalaman. Pakar subjek kami telah menerajui banyak implementasi AI di bidangnya dan mempelajari pelajaran berharga sepanjang perjalanan, dan tujuan utamanya adalah untuk membantu anda mencapai tujuan anda.
Dengan pakar domain mengenal pasti, mengatur, mengkategorikan, dan melabel data untuk anda, anda tahu maklumat yang digunakan untuk melatih algoritma anda dapat menghasilkan hasil yang terbaik. Kami juga melakukan jaminan kualiti secara berkala untuk memastikan data memenuhi piawaian tertinggi dan akan berfungsi seperti yang diharapkan tidak hanya di makmal, tetapi juga dalam situasi di dunia nyata.
4. Garis masa pembangunan yang dipercepat
Pengembangan AI tidak berlaku dalam sekelip mata, tetapi dapat terjadi lebih cepat ketika anda bekerjasama dengan Shaip. Pengumpulan dan anotasi data dalaman mewujudkan hambatan operasi yang signifikan yang menahan proses pembangunan yang selebihnya. Bekerja dengan Shaip memberi anda akses segera ke perpustakaan data siap pakai kami yang luas, dan pakar kami dapat memperoleh segala jenis input tambahan yang anda perlukan dengan pengetahuan industri dan rangkaian global kami yang mendalam. Tanpa beban sumber dan anotasi, pasukan anda dapat segera mengembangkan pembangunan sebenar, dan model latihan kami dapat membantu mengenal pasti ketidaktepatan awal untuk mengurangkan lelaran yang diperlukan untuk memenuhi tujuan ketepatan.
Sekiranya anda tidak bersedia melakukan outsourcing semua aspek dalam pengurusan data anda, Shaip juga menawarkan platform berasaskan awan yang membantu pasukan menghasilkan, mengubah, dan memberi anotasi pelbagai jenis data dengan lebih berkesan, termasuk sokongan untuk gambar, video, teks, dan audio . ShaipCloud merangkumi pelbagai alat pengesahan dan alur kerja intuitif, seperti penyelesaian yang dipatenkan untuk mengesan dan memantau beban kerja, alat transkripsi untuk menyalin rakaman audio yang rumit dan sukar, dan komponen kawalan kualiti untuk memastikan kualiti tanpa kompromi. Yang terbaik, ia boleh diskalakan, sehingga dapat berkembang seiring dengan bertambahnya permintaan dari projek anda.
Zaman inovasi AI baru bermula, dan kita akan melihat kemajuan dan inovasi yang luar biasa pada tahun-tahun mendatang yang berpotensi untuk membentuk semula seluruh industri atau bahkan mengubah masyarakat secara keseluruhan. Di Shaip, kami ingin menggunakan kepakaran kami untuk berfungsi sebagai kekuatan transformatif, membantu syarikat yang paling revolusioner di dunia memanfaatkan kekuatan penyelesaian AI untuk mencapai tujuan yang bercita-cita tinggi.
Kami mempunyai pengalaman yang mendalam dalam aplikasi kesihatan dan AI percakapan, tetapi kami juga mempunyai kemahiran yang diperlukan untuk melatih model untuk hampir semua jenis aplikasi. Untuk maklumat lebih lanjut mengenai bagaimana Shaip dapat membantu mengambil projek anda dari idea hingga pelaksanaan, lihat banyak sumber yang ada di laman web kami atau hubungi kami hari ini.
