
Model Bahasa Besar baru-baru ini mendapat perhatian besar selepas kes penggunaan yang sangat cekap ChatGPT menjadi kejayaan dalam sekelip mata. Melihat kejayaan ChatGPT dan ChatBots yang lain, ramai orang dan organisasi telah berminat untuk meneroka teknologi yang menguasai perisian tersebut.
Model Bahasa Besar adalah tulang belakang di sebalik perisian ini yang membolehkan pelbagai aplikasi Pemprosesan Bahasa Semulajadi seperti terjemahan mesin, pengecaman pertuturan, menjawab soalan dan ringkasan teks. Biar kami mengetahui lebih lanjut tentang LLM dan cara anda boleh mengoptimumkannya untuk hasil yang terbaik.
Apakah Model Bahasa Besar atau ChatGPT?
Model Bahasa Besar ialah model pembelajaran mesin yang memanfaatkan rangkaian saraf tiruan dan silo data yang besar untuk menggerakkan aplikasi NLP. Selepas latihan mengenai jumlah data yang besar, LLM memperoleh keupayaan untuk menangkap pelbagai kerumitan bahasa semula jadi, yang digunakan selanjutnya untuk:
- Penjanaan teks baharu
- Rumusan artikel dan petikan
- Pengekstrakan data
- Menulis semula atau menghuraikan teks
- Pengelasan data
Beberapa contoh popular LLM ialah BERT, Chat GPT-3 dan XLNet. Model ini dilatih mengenai ratusan juta teks dan boleh memberikan penyelesaian yang berbaloi kepada semua jenis pertanyaan pengguna yang berbeza.
Kes Penggunaan Popular Model Bahasa Besar
Berikut ialah beberapa kes penggunaan LLM teratas dan paling lazim:
Penjanaan Teks
Model Bahasa Besar menggunakan kecerdasan buatan dan pengetahuan linguistik komputasi untuk menjana teks bahasa semula jadi secara automatik dan melengkapkan pelbagai keperluan pengguna komunikatif seperti menulis artikel, lagu, atau berbual dengan pengguna.
Terjemahan Mesin
LLM juga boleh digunakan untuk menterjemah teks antara mana-mana dua bahasa. Model tersebut memanfaatkan algoritma pembelajaran mendalam, seperti rangkaian saraf berulang, untuk mempelajari struktur bahasa sumber dan bahasa sasaran. Sehubungan itu, ia digunakan untuk menterjemah teks sumber ke dalam bahasa sasaran.
Penciptaan Kandungan
LLM kini telah membolehkan mesin mencipta kandungan yang koheren dan logik yang boleh digunakan untuk menjana catatan blog, artikel dan bentuk kandungan lain. Model menggunakan pengetahuan pembelajaran mendalam mereka yang luas untuk memahami dan menyusun kandungan dalam format yang unik dan boleh dibaca untuk pengguna.
Analisis Sentimen
Ia merupakan kes penggunaan Model Bahasa Besar yang menarik di mana model ini dilatih untuk mengenal pasti dan mengklasifikasikan keadaan emosi dan sentimen dalam teks berlabel. Perisian ini boleh mengesan emosi seperti positif, negatif, berkecuali dan sentimen kompleks lain yang boleh membantu mendapatkan cerapan tentang pendapat dan ulasan pelanggan tentang produk dan perkhidmatan yang berbeza.
Pemahaman, Rumusan, & Klasifikasi Teks
LLM menyediakan rangka kerja praktikal untuk perisian AI memahami teks dan konteksnya. Dengan melatih model untuk memahami dan menganalisis timbunan data yang besar, LLM membolehkan model AI untuk memahami, meringkaskan dan juga mengelaskan teks dalam bentuk dan corak yang berbeza.
Menjawab Soalan
Model Bahasa Besar membolehkan sistem QA mengesan dan bertindak balas dengan tepat kepada pertanyaan bahasa semula jadi pengguna. Salah satu aplikasi yang paling popular bagi kes penggunaan ini ialah ChatGPT dan BERT, yang menganalisis konteks pertanyaan dan mencari melalui korpus besar teks untuk mencari jawapan yang berkaitan kepada pertanyaan pengguna.
[ Baca Juga: Masa Depan Pemprosesan Bahasa: Model & Contoh Bahasa Besar ]

3 Syarat Penting untuk Menjadikan LLM Berjaya
Tiga syarat berikut mesti dipenuhi dengan tepat untuk meningkatkan kecekapan dan menjadikan Model Bahasa Besar anda berjaya:
Kehadiran Sejumlah Besar Data untuk Latihan Model
LLM memerlukan sejumlah besar data untuk melatih model yang memberikan hasil yang cekap dan optimum. Terdapat kaedah khusus, seperti pembelajaran pemindahan dan pra-latihan diselia sendiri, yang LLM memanfaatkan untuk meningkatkan prestasi dan ketepatannya.
Membina Lapisan Neuron untuk Memudahkan Corak Kompleks kepada Model
Model Bahasa Besar mesti terdiri daripada pelbagai lapisan neuron yang dilatih khas untuk memahami corak rumit dalam data. Neuron dalam lapisan yang lebih dalam boleh memahami corak yang kompleks dengan lebih baik daripada lapisan yang lebih cetek. Model ini boleh mempelajari perkaitan antara perkataan, topik yang muncul bersama, dan perkaitan antara bahagian pertuturan.
Pengoptimuman LLM untuk Tugasan Khusus Pengguna
LLM boleh diubah suai untuk tugas tertentu dengan menukar bilangan lapisan, neuron dan fungsi pengaktifan. Sebagai contoh, model yang meramalkan perkataan berikut dalam ayat biasanya menggunakan lebih sedikit lapisan dan neuron daripada model yang direka untuk menjana ayat baharu dari awal.
Contoh Popular Model Bahasa Besar
Berikut ialah beberapa contoh utama LLM yang digunakan secara meluas dalam menegak industri yang berbeza:
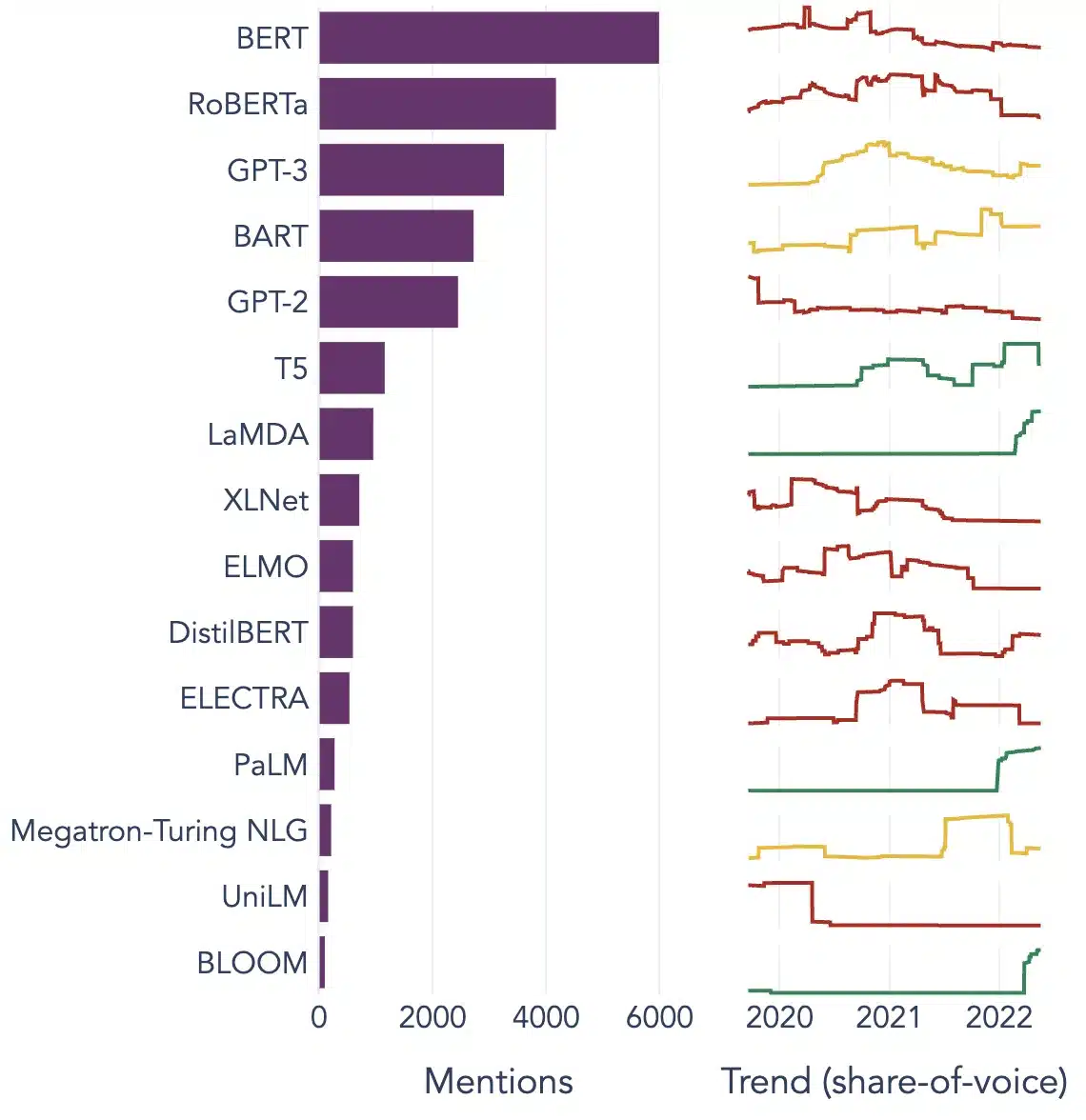
Imej Source: Ke arah Sains data
Kesimpulan
LLM melihat potensi untuk merevolusikan NLP dengan menyediakan keupayaan dan penyelesaian pemahaman bahasa yang mantap dan tepat yang memberikan pengalaman pengguna yang lancar. Walau bagaimanapun, untuk menjadikan LLM lebih cekap, pembangun mesti memanfaatkan data pertuturan berkualiti tinggi untuk menjana hasil yang lebih tepat dan menghasilkan model AI yang sangat berkesan.
Shaip ialah salah satu penyelesaian teknologi AI terkemuka yang menawarkan pelbagai data pertuturan dalam lebih 50 bahasa dan berbilang format. Ketahui lebih lanjut tentang LLM dan ambil panduan tentang projek anda daripada Pakar Shaip hari ini.


